배치 시스템 성능 분석: 개선 임팩트 측정과 개발자 성장 회고 (4)
큐 시스템 개선의 임팩트를 메모리, CPU, 네트워크, 이벤트 루프 지표로 측정하고 분석했습니다. 또한 기술 코드/설계, 기술 운영, 제품, 커뮤니케이션 관점에서 프로젝트를 회고하며 개발자로서의 성장을 점검합니다.
1. 들어가며
이전 글들에서는 주로 큐와 배치 시스템을 어떻게 설계하고, 어떤 지표로 성능과 임팩트를 측정할 수 있는지에 초점을 맞췄습니다.
이번 글에서는 그 연장선에서, 시스템의 개선 임팩트 측정 및 분석 뿐만 아니라 그 시스템을 만드는 나 자신을 어떤 기준으로 바라볼 것인가에 대해 정리해보려고 합니다.
같은 문제를 풀더라도 어떤 선택을 했는지, 그 선택이 실제로 어떤 결과를 만들었는지를 따져보는 일은 결국 개발자로서 나는 어디쯤 와 있는가를 점검하는 일과 맞닿아 있기 때문이에요. 또한 저는 좋은 개발자란 오버엔지니어링과 언더엔지니어링을 잘 구분하며, 비즈니스 요구사항을 우직하게 잘 소화해내는 개발자라고 생각하거든요.
내가 과연 이러한 생각에 맞는 사람일지, 더 노력해야하는지 이 글과 이번 프로젝트를 통해 잘 정리해보려고 합니다.
그래서 이 글에서는 일할 때 중요한 다섯 가지 축인 기술 코드/설계, 기술 운영, 제품, 커뮤니케이션를 기준으로, 이번에 해본 일들을 다시 훑어보며 스스로를 평가해보려 해요. 내가 잘한 점이나 못한 점을 회고한다기보다는, 앞으로는 이런 관점으로 나를 바라보고 싶다는 의미에 가까운 회고에 가깝습니다.
이러한 글들을 매 프로젝트마다 남겨두면 나중에 비슷한 선택의 기로에 섰을 때, 예전의 나를 떠올리며 그때는 이렇게 생각했고, 지금은 어디까지 왔는가를 비교해볼 수 있는 기준점 정도가 되면 좋겠습니다.
2. 최적화, 임팩트 측정
먼저 지표들을 살펴보려고 합니다. 이전 글에서 살펴보았던 지표가 어떻게 변화하였는지 살펴보려고 합니다.
메모리
평균 메모리 사용량
AS-IS
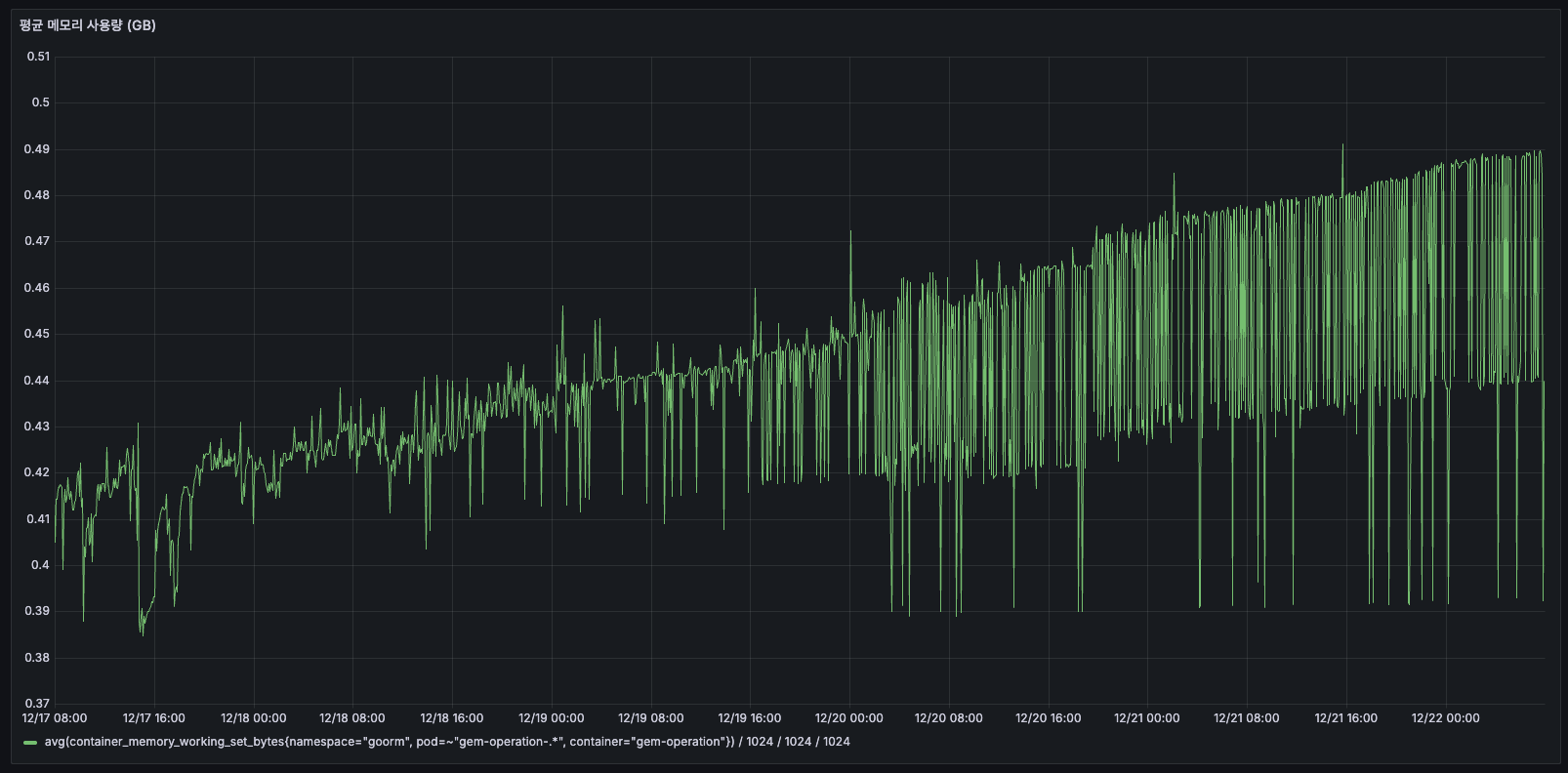
도입 이전에는 약 0.4GB ~ 0.5GB 수준이지만, 계속해서 우상향하고 있었습니다.
TO-BE
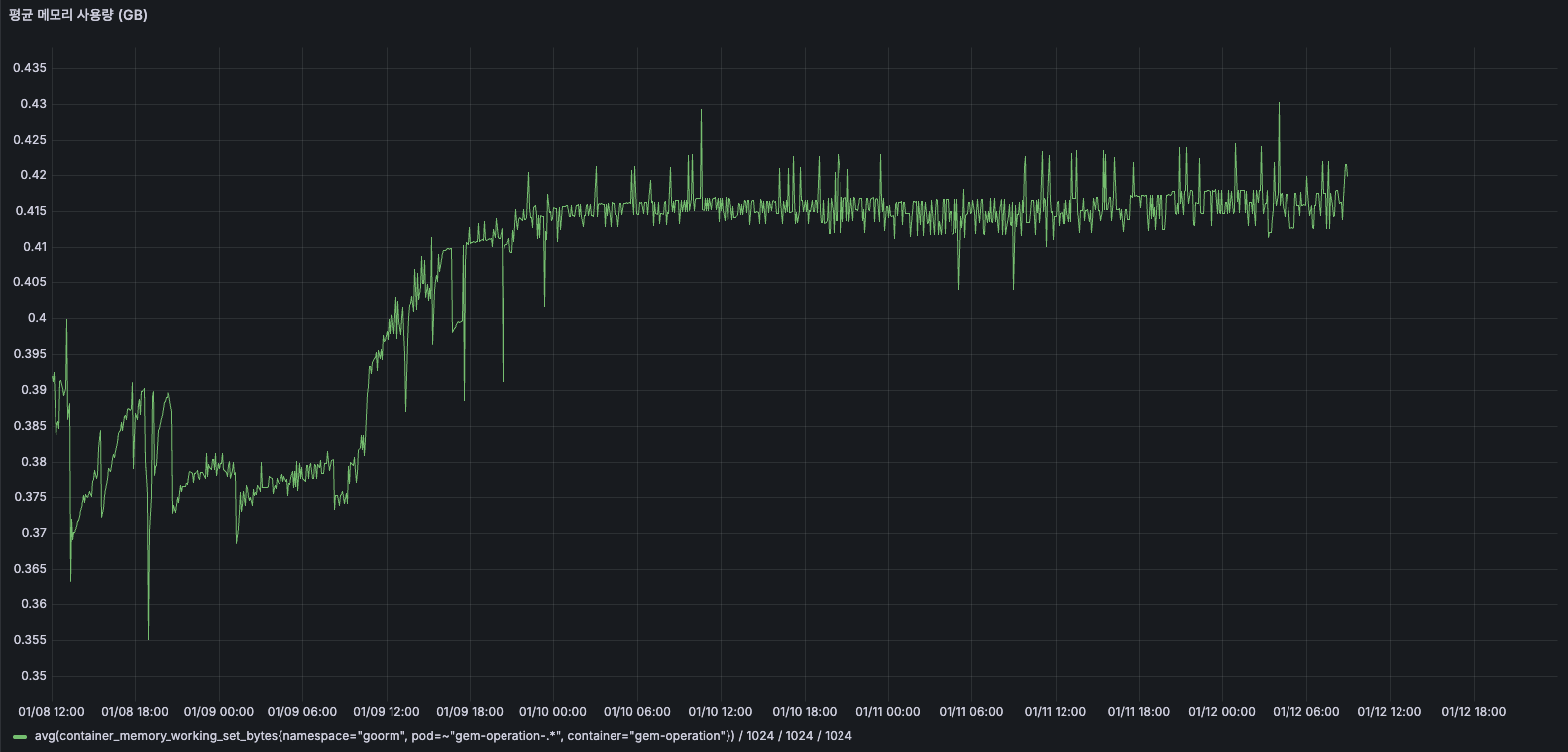
도입 이후 약 0.4GB ~ 0.425GB 수준을 유지하고 있으며, 이전과 달리 우상향하는 패턴이 사라졌습니다.
최대 메모리 사용량
AS-IS
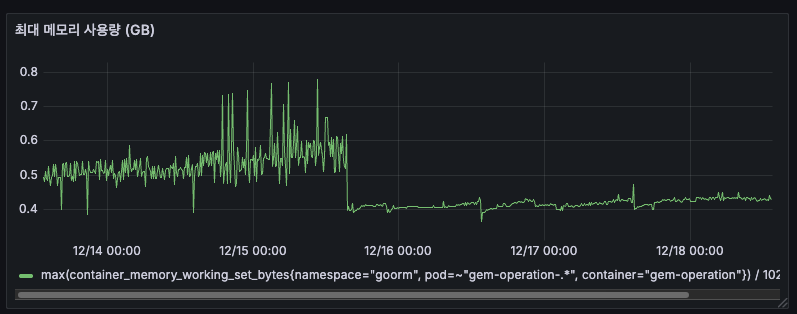
도입 이전 12/15에는 최대 0.7GB까지 튀며 우상향하고 있었습니다. 16일 이후에 안정화 된 것은 배포 이후 새로 앱이 뜨면서 안정화된 것입니다.
이는 일시적으로 해결된 것일 뿐, 5일간 최대 메모리 사용량이 지속적으로 증가하여 0.54GB까지 도달했습니다.
평균 메모리와 함께 우상향하는 패턴으로 보아, 메모리 누수를 의심했었습니다.
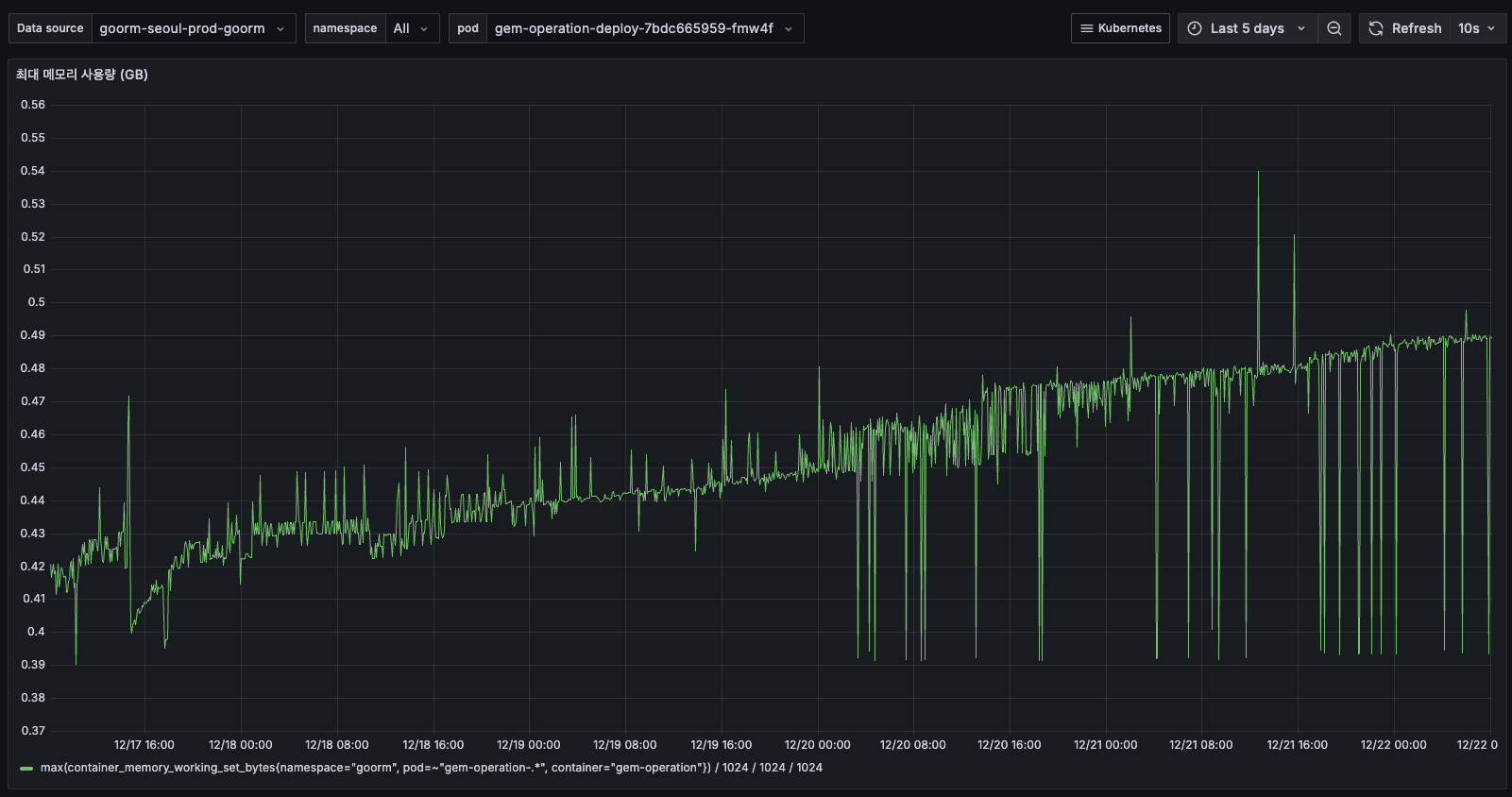
TO-BE
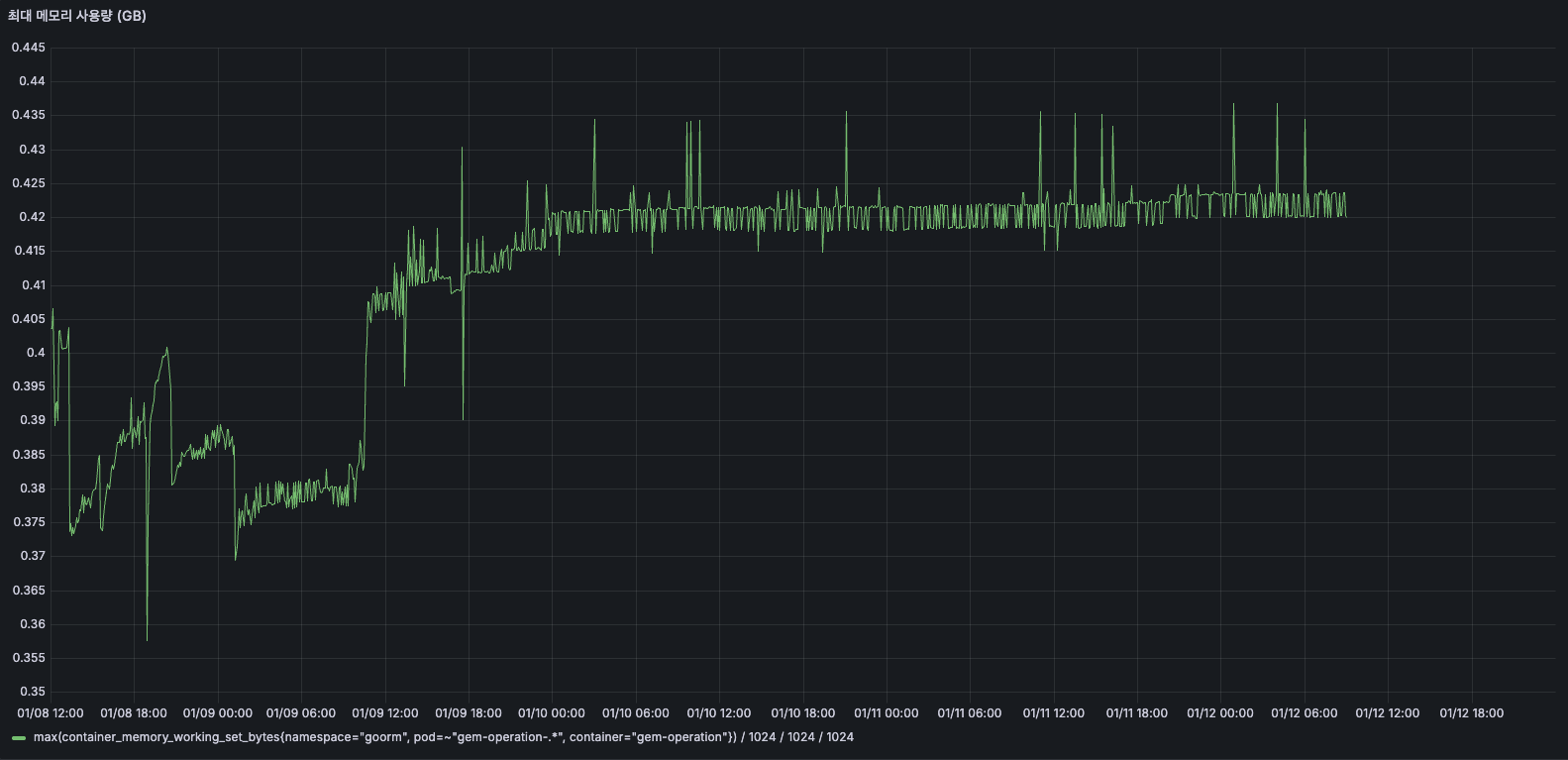
도입 이후 10일부터 0.4GB ~ 0.435GB 수준을 안정적으로 유지하고 있으며, 지속적인 우상향 패턴이 더 이상 관찰되지 않습니다.
메모리 사용량
AS-IS
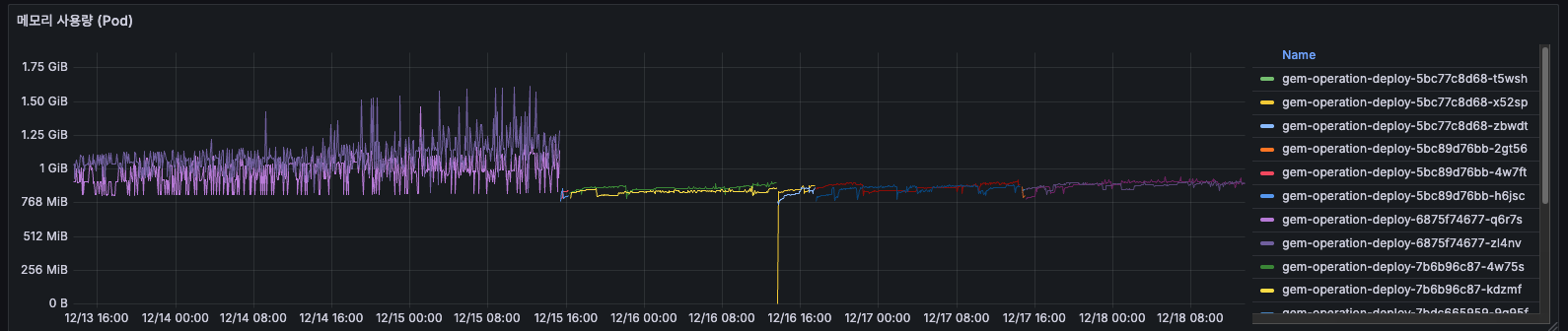
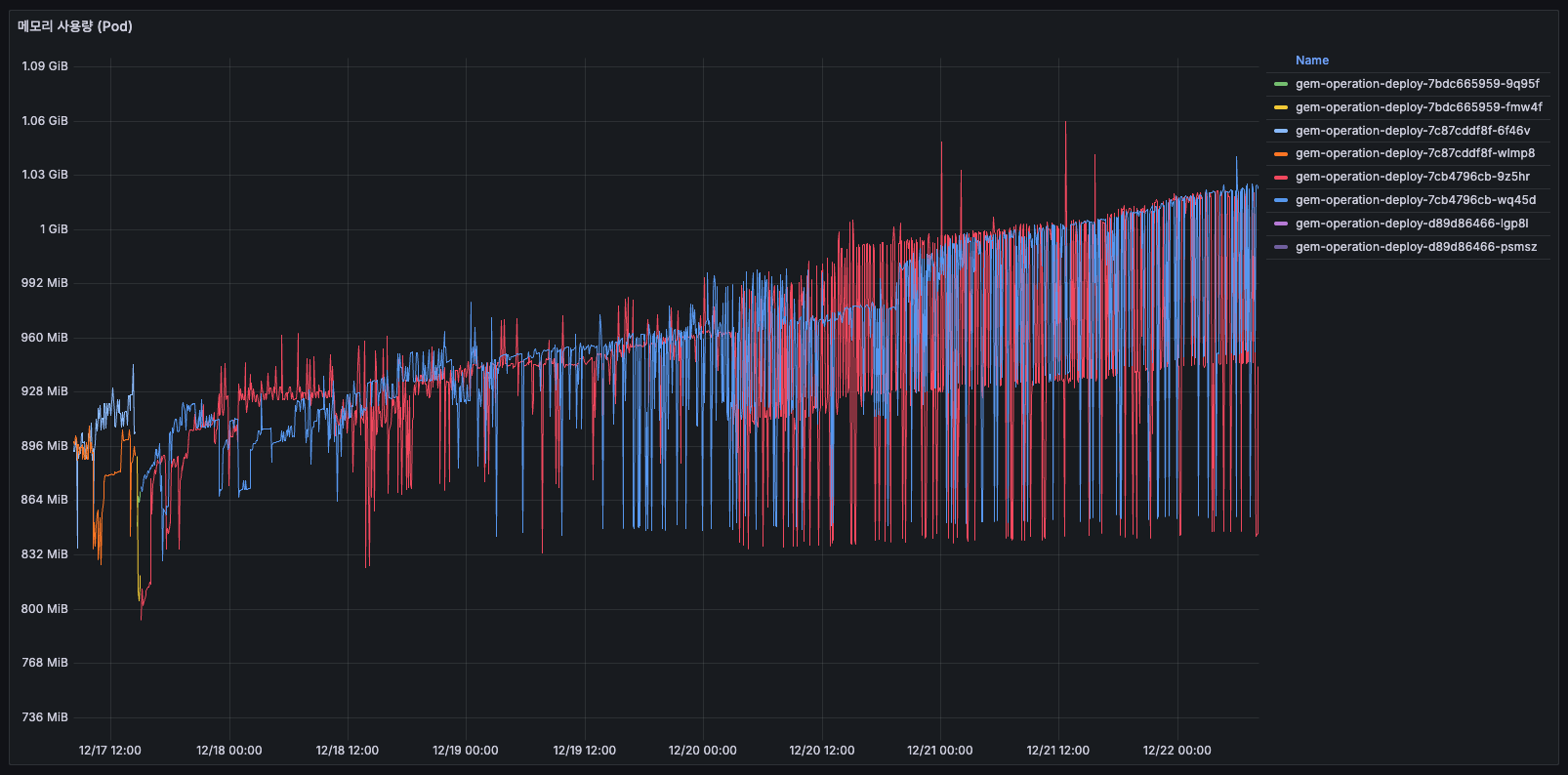
12/14 초반에는 약 1GiB를 사용하고 있었습니다. 12/16 12:00 이후 갑자기 0으로 떨어지고, 새로운 Pod들만 보이게 되었습니다.
배포로 인해 Pod 전체가 교체되었습니다. 구 Pod는 11.5 GiB를 사용하고 있었고, 신 Pod는 0.751 GiB를 사용하여 약 25~33% 메모리가 감소했습니다.
TO-BE
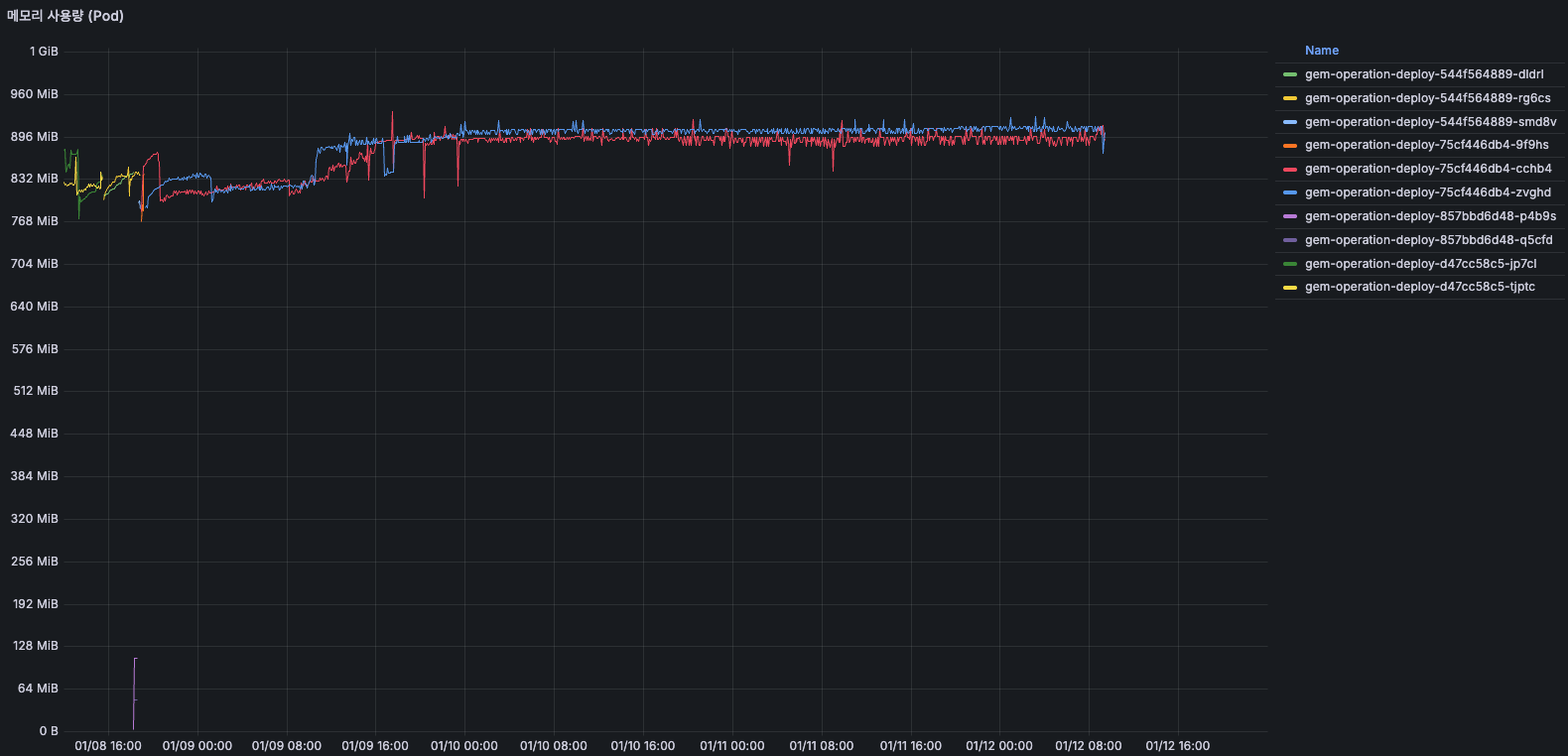
이전에 1GiB를 넘어 계속 상승하던 패턴이 사라지고, 현재는 약 900MiB 수준에서 안정적으로 유지되고 있습니다.
CPU
평균 CPU 사용량
AS-IS
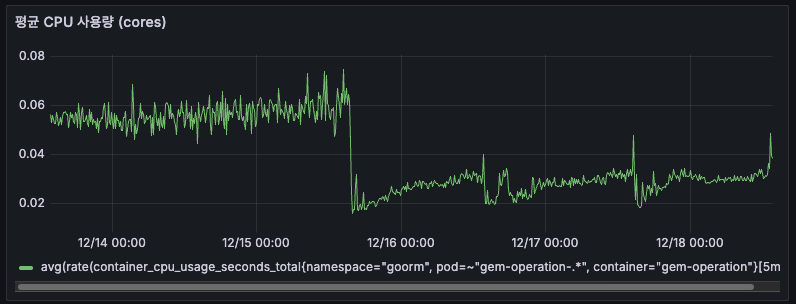
12/14 ~ 12/15에는 약 0.05~0.06 cores를 사용하고 있었습니다. 12/16 배포 후에는 약 0.03 cores로 감소하였고, 이후 안정적으로 0.03 cores를 유지하고 있었습니다. 배포 후 CPU 사용량도 약 50% 감소하여 메모리와 동일한 패턴을 보였습니다.
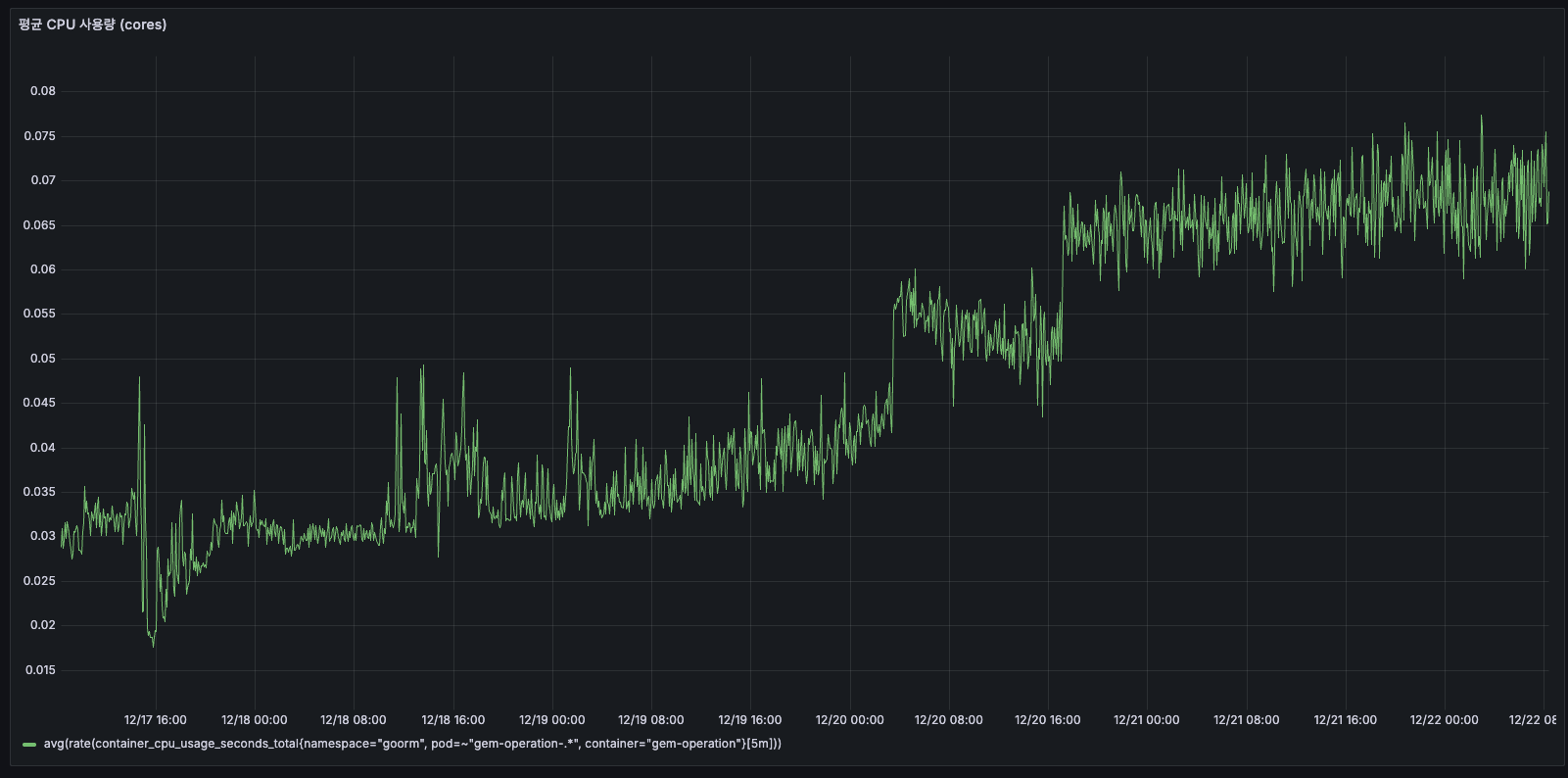
TO-BE
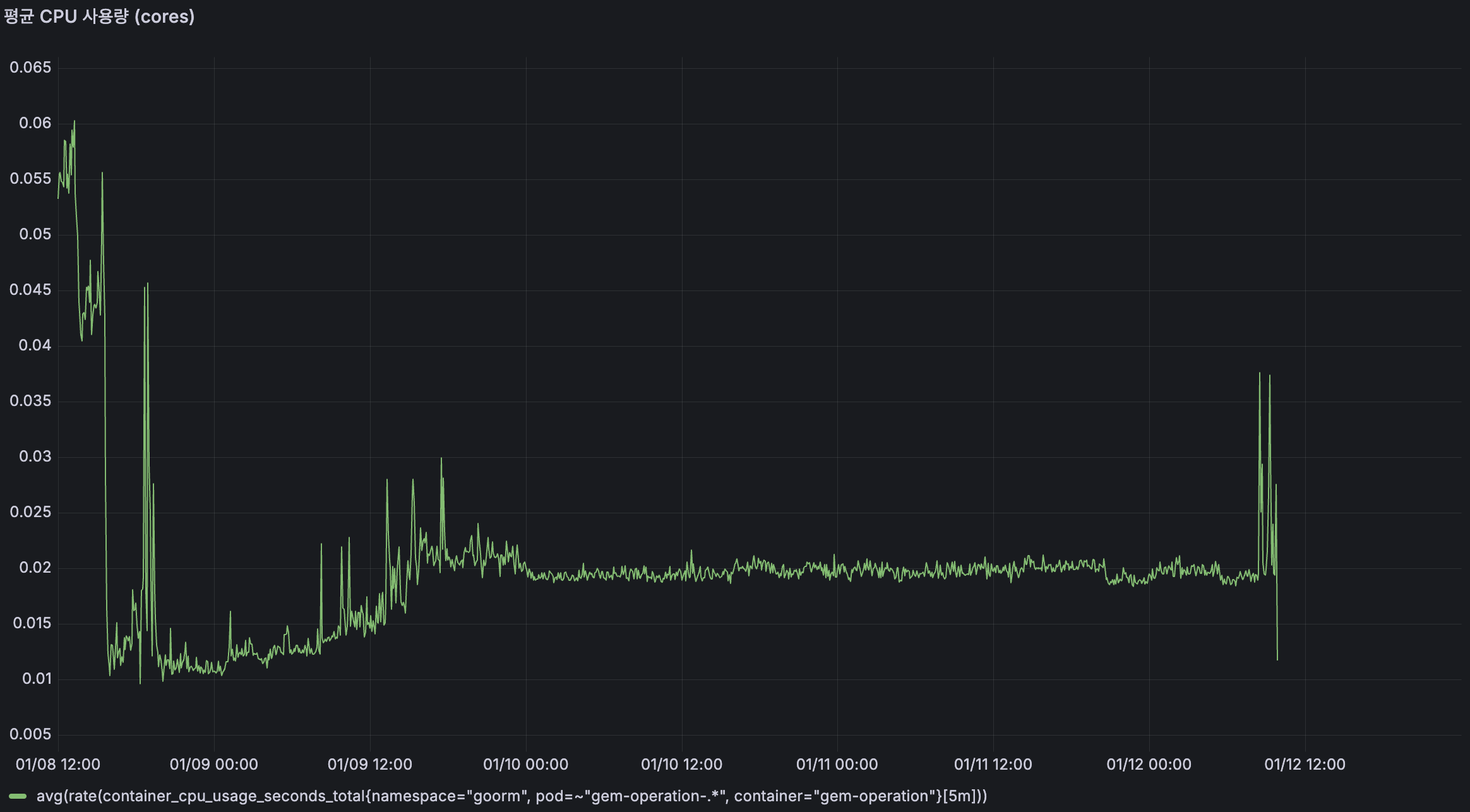
이전과 달리 우상향 패턴이 사라지고, 약 0.02 cores 수준에서 안정적으로 유지되고 있습니다.
최대 CPU 사용량
AS-IS
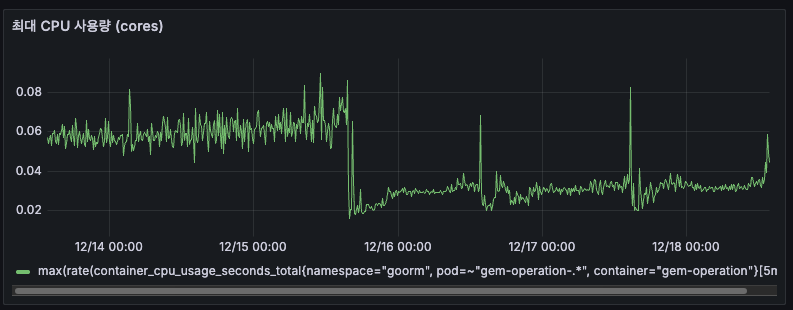
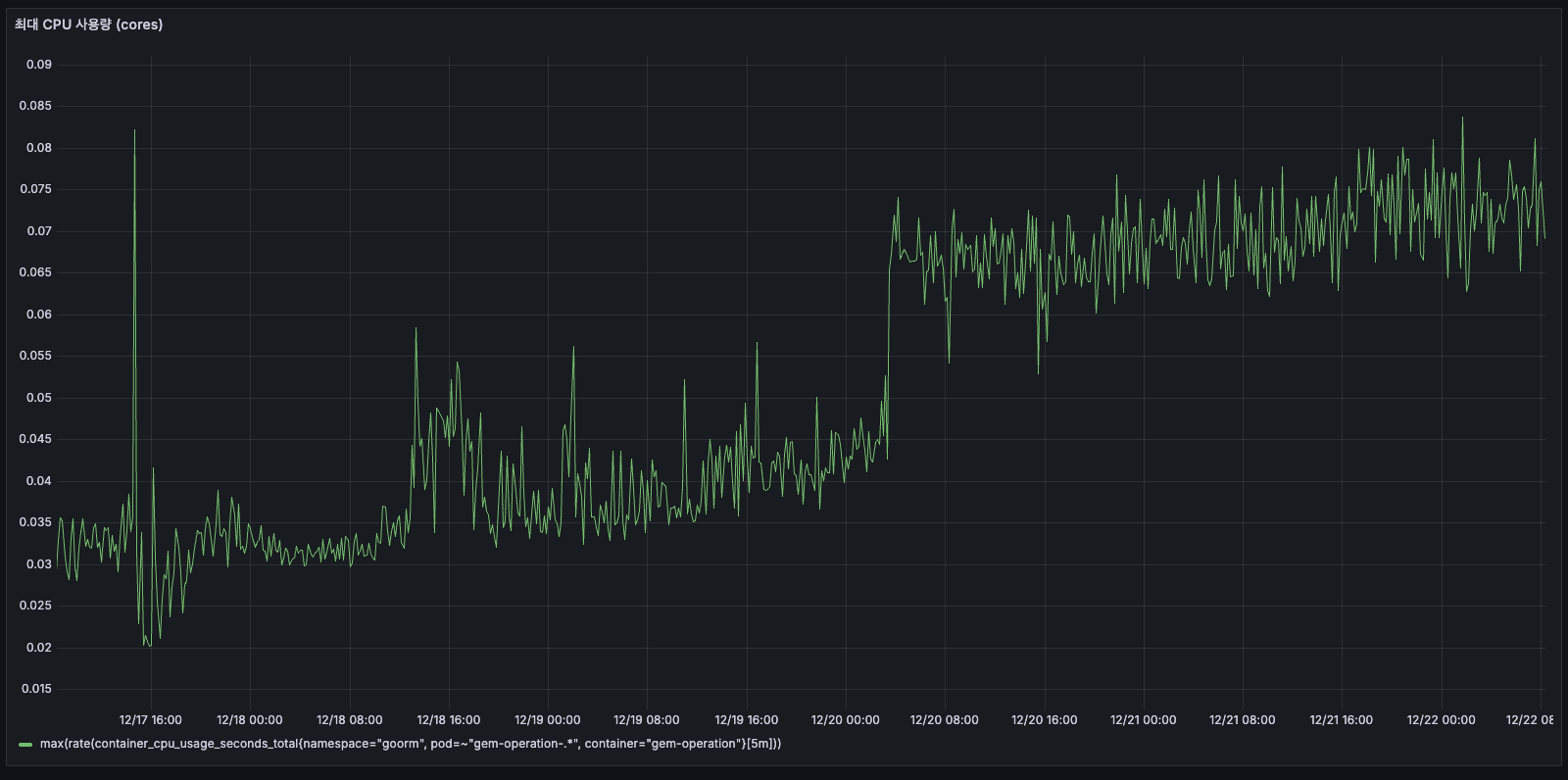
전체적으로 0.06~0.08 cores를 사용하고 있었고, 간헐적인 스파이크로 최대 0.09 cores까지 올라가기도 하였습니다. 피크 타임에도 0.08 cores로 8%만 사용하고 있었습니다.
TO-BE
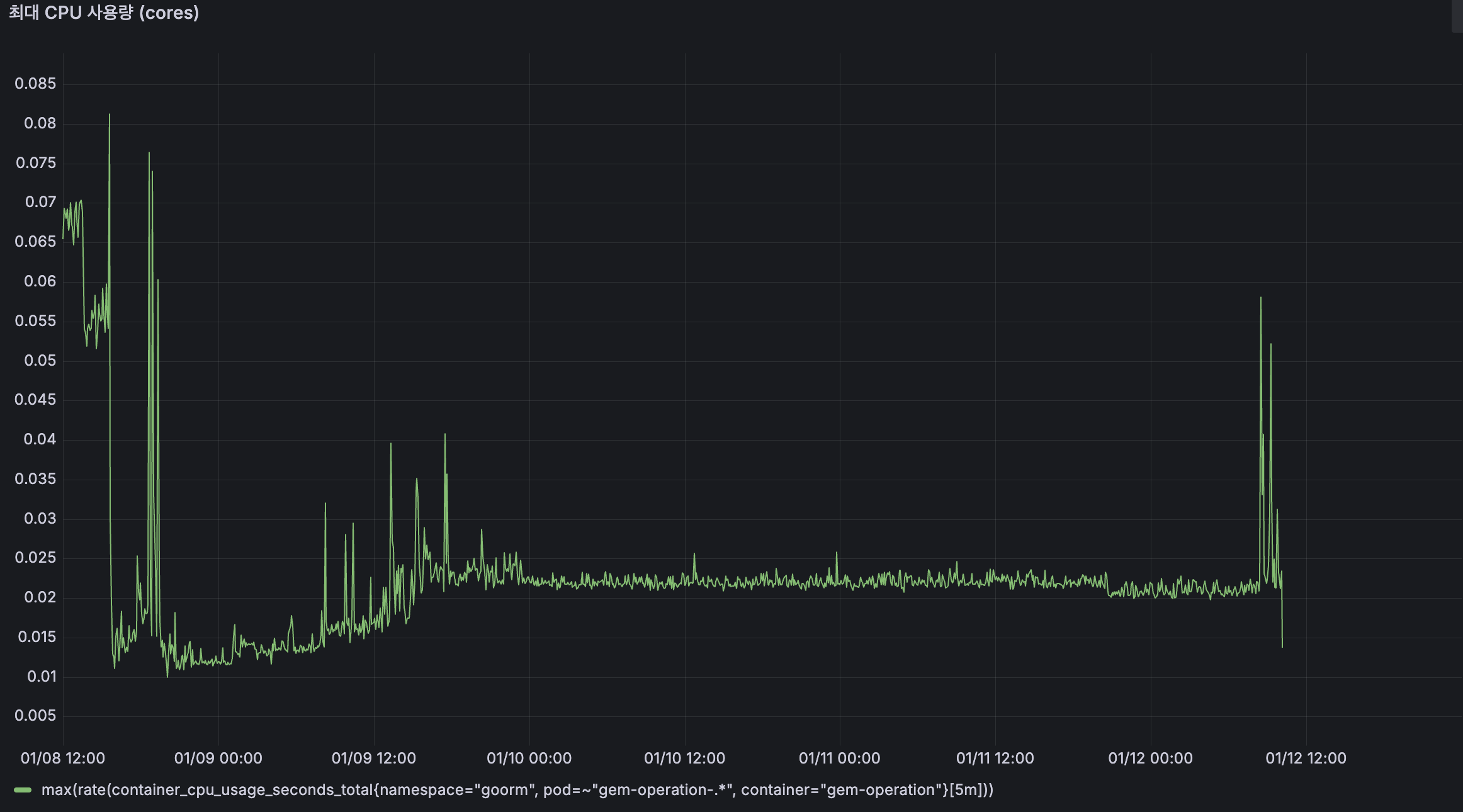
최대 CPU 사용량도 우상향 패턴이 사라지고, 약 0.02 cores 수준에서 안정적으로 유지되고 있습니다.
CPU 사용량 (Pod)
AS-IS

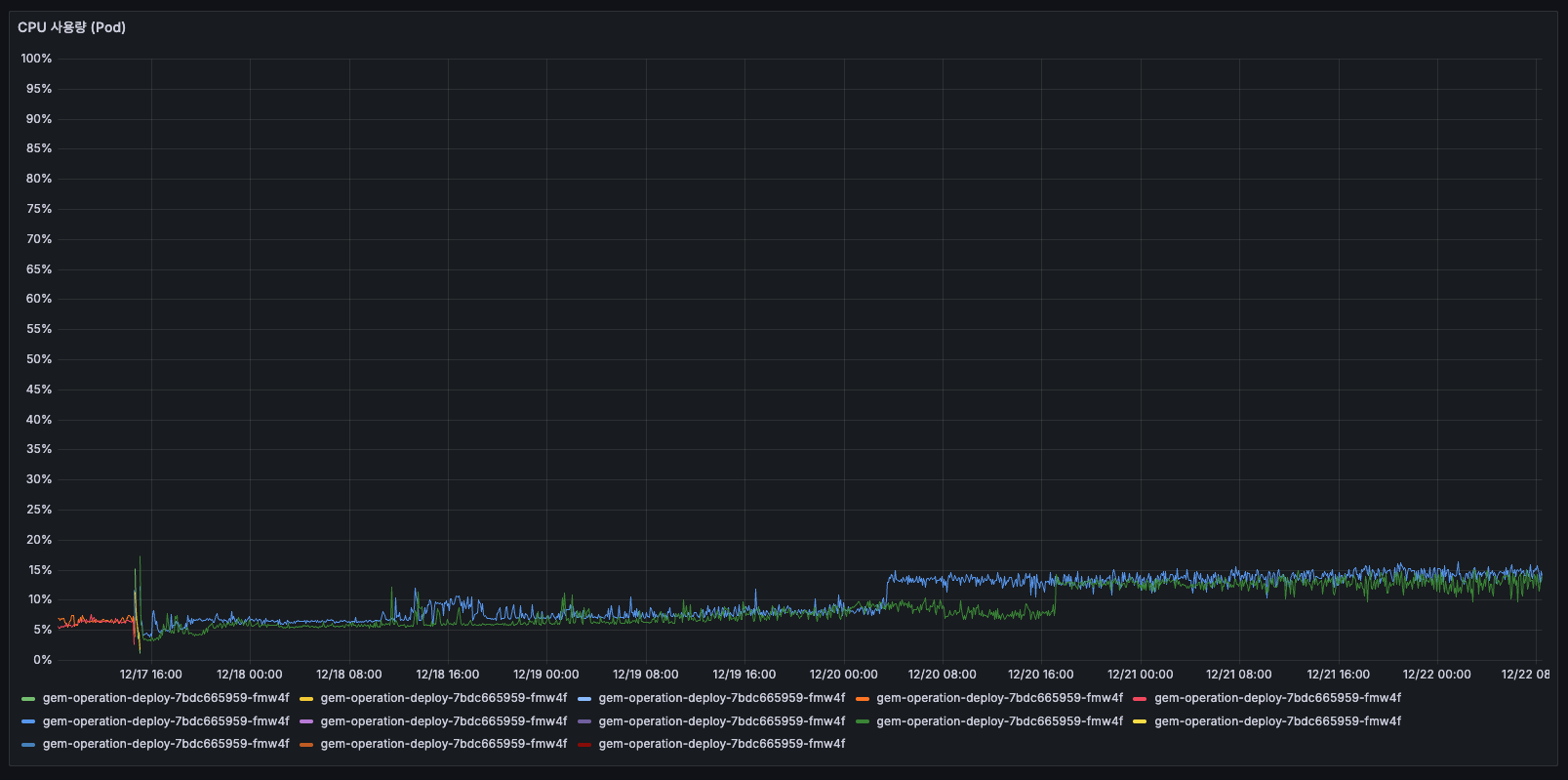
5일간 Pod CPU 추세
모든 Pod가 10% 이하로 사용하고 있었고, 거의 바닥에 붙어있는 상태였습니다. 12/16 이후 여러 Pod로 분산되었습니다.
TO-BE
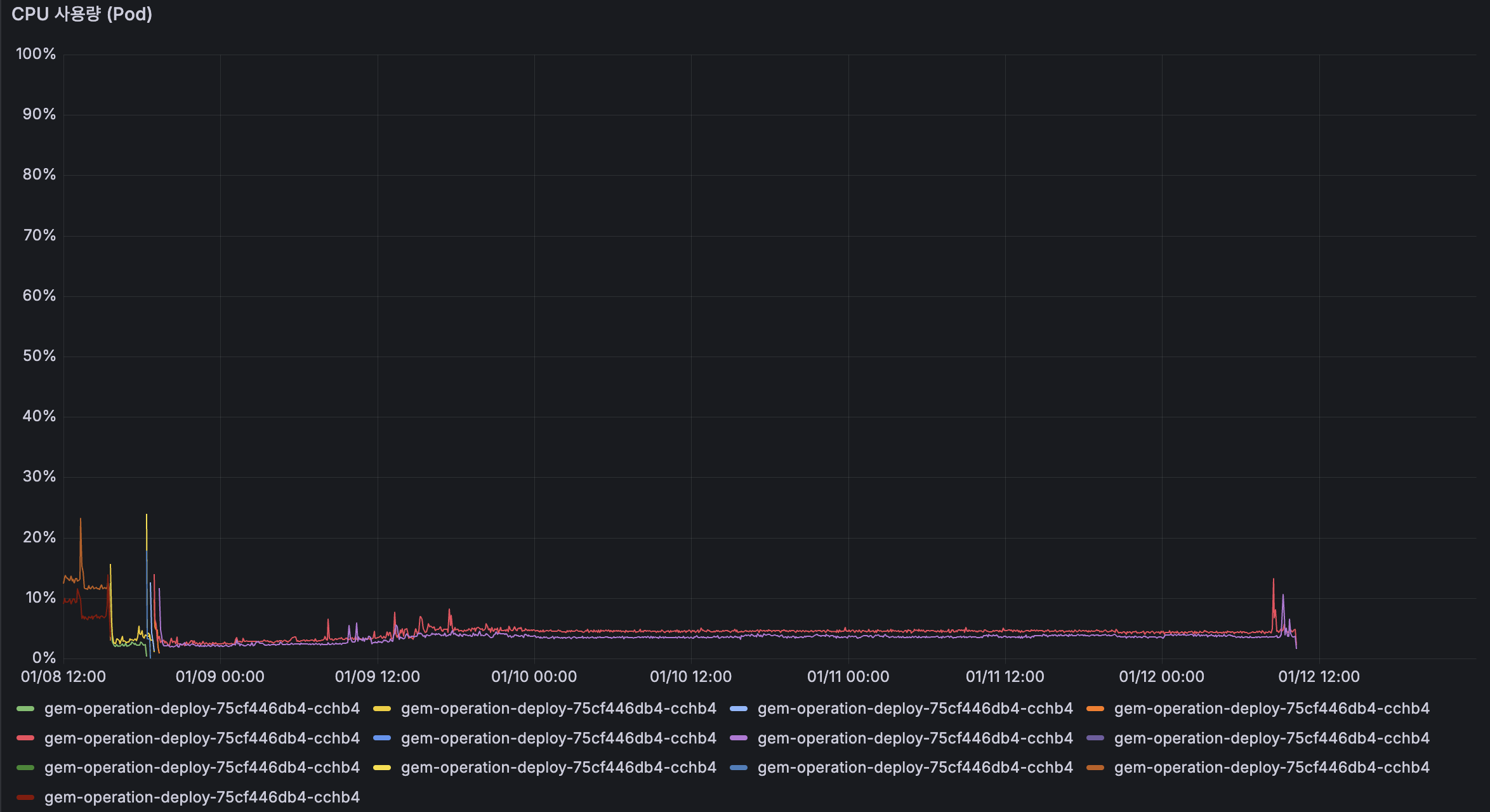
Pod CPU 사용률이 일시적으로 8%까지 상승한 적이 있지만, 전반적으로는 모든 Pod에서 약 4% 수준의 낮은 사용률을 보이고 있습니다.
패킷
패킷 전송률
AS-IS
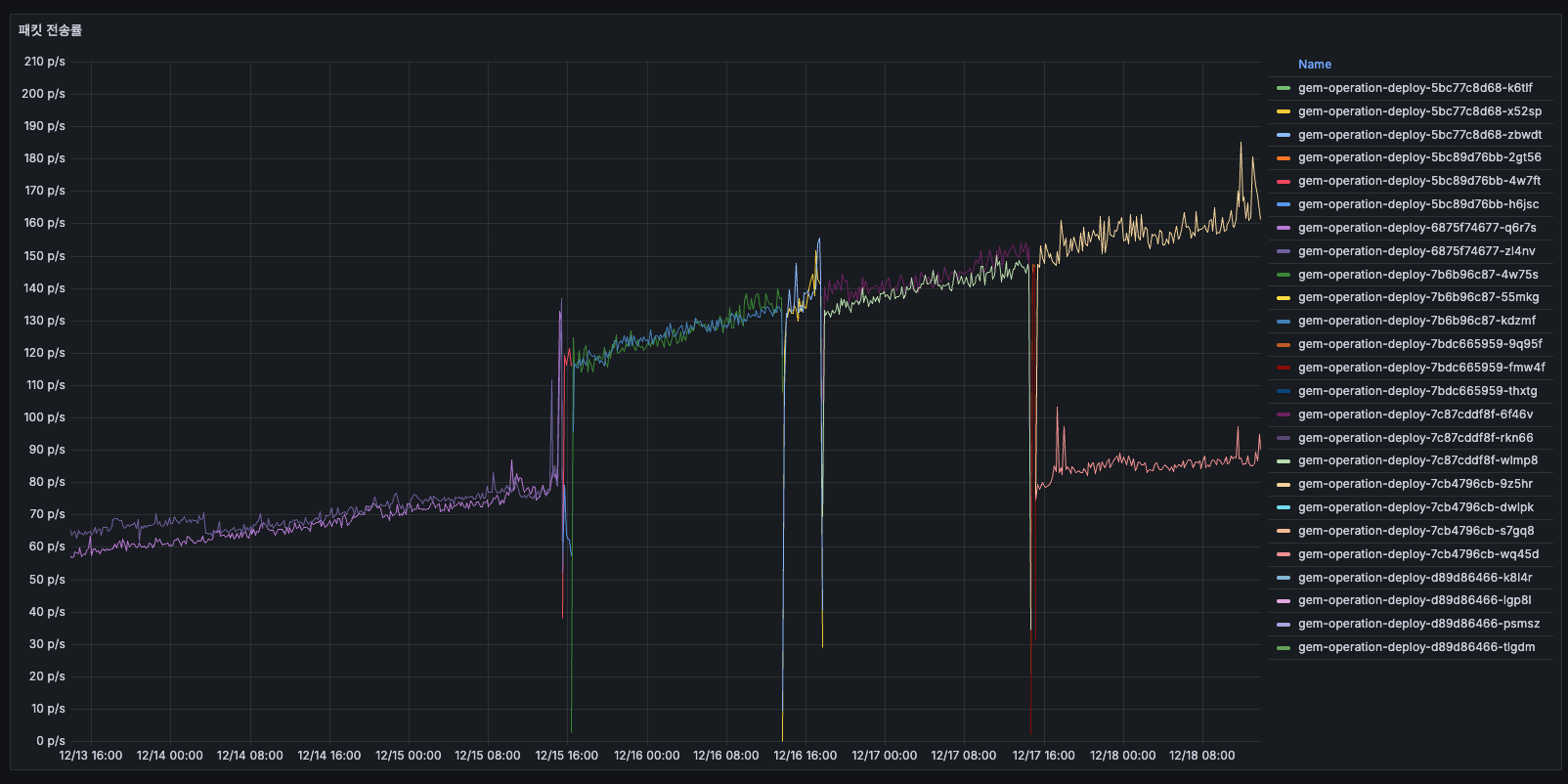
12/14 초반에는 약 5060 p/s를 사용하고 있었고, 12/15에는 점진적으로 증가하여 100150 p/s까지 올라갔습니다. 12/16 00:00에 Pod 교체로 리셋되었고, 이후 75~100 p/s로 안정화되었습니다. 배포 전에는 패킷 수가 계속 증가하고 있었고, 배포 후에는 낮아지고 안정화되었습니다.
메모리/CPU와 동일한 패턴으로 보였습니다.
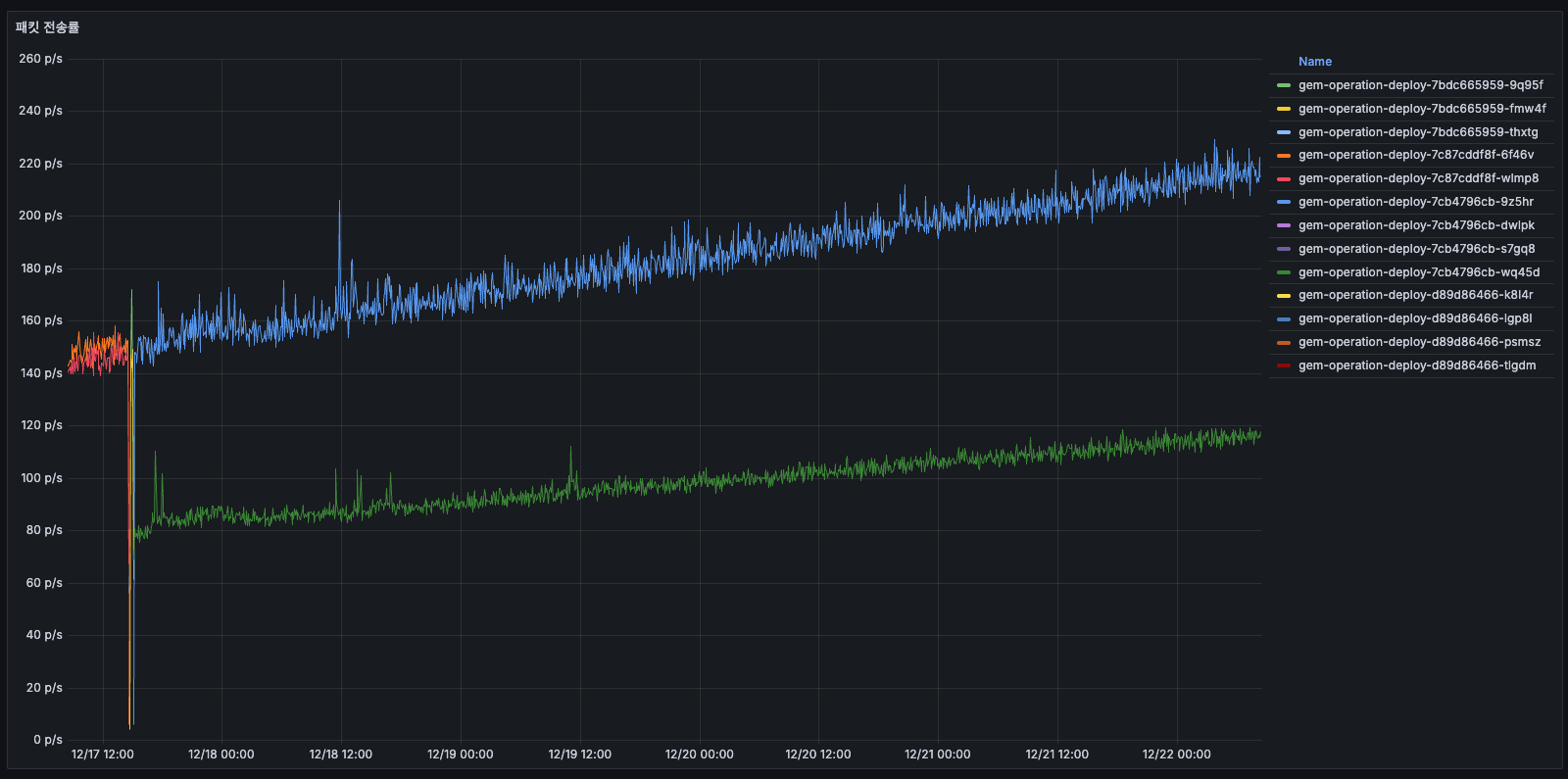
TO-BE
전송률이 크게 개선되었습니다. 이전에 우상향하며 220 p/s까지 상승하던 전송률이 현재는 안정적으로 약 20 p/s를 유지하고 있으며, 피크 타임에만 일시적으로 상승하는 것을 확인할 수 있습니다. 해당 시점인 12일은 모집 마감일이어서 사용자 제출이 집중되는 시기였습니다.
큐 개선을 통해 스케줄러가 매 1분마다 수행하던 요청 및 전송 작업이 감소했고, 이로 인해 외부 API 호출과 전송량을 줄일 수 있었던 것으로 보입니다.
패킷 수신률
AS-IS
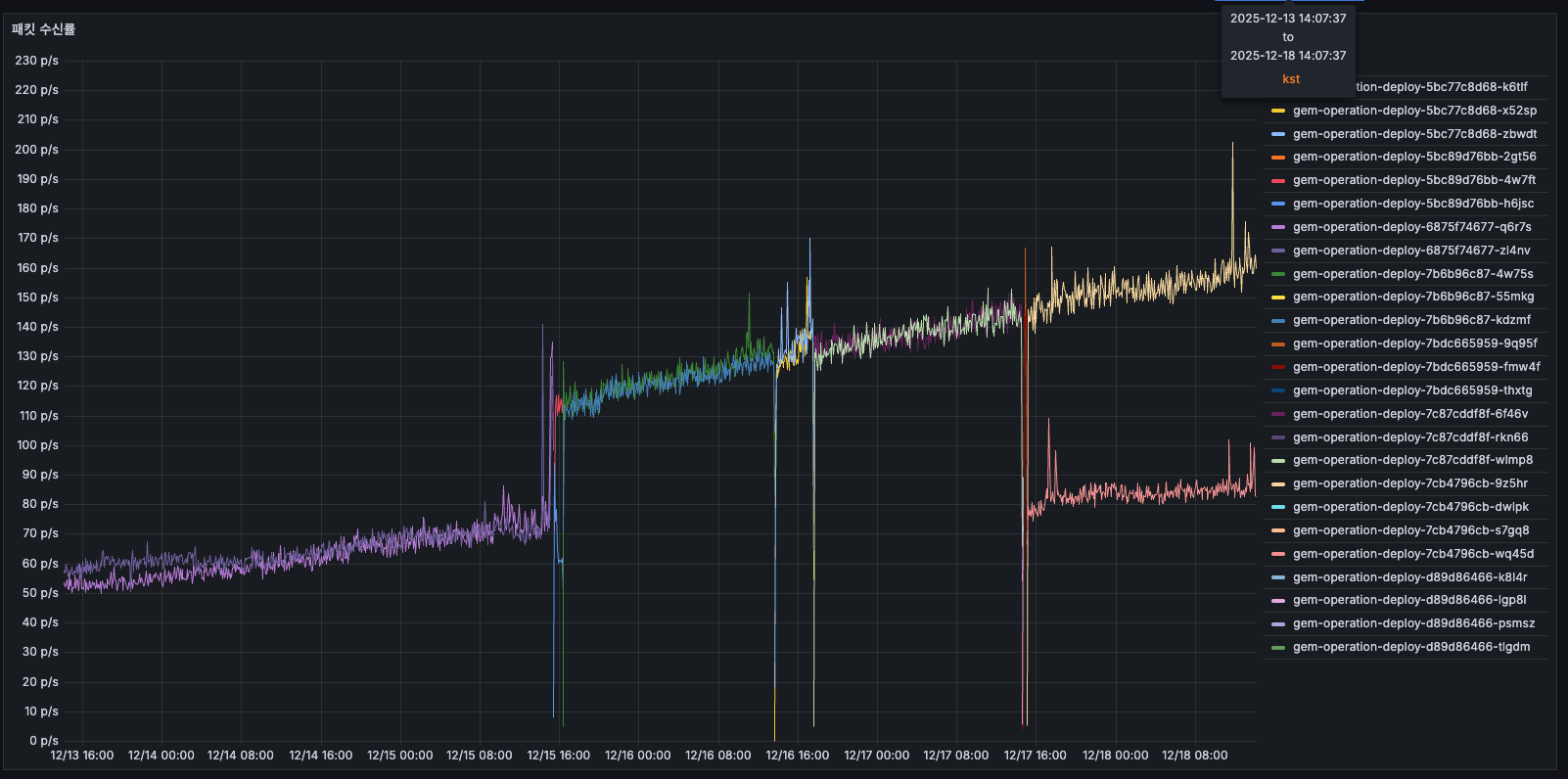
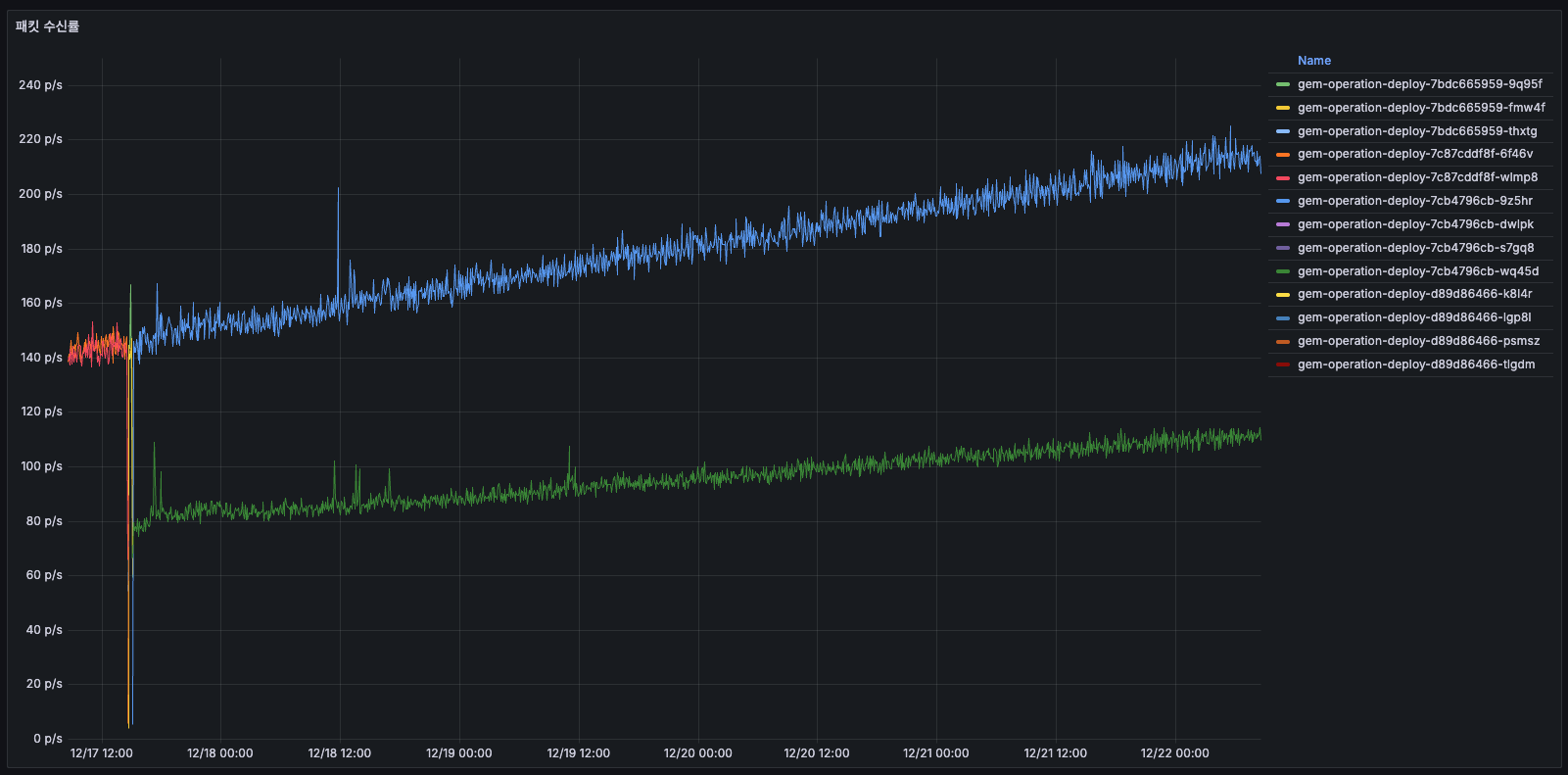
12/14에는 약 50 p/s를 사용하고 있었고, 12/1512/16에는 증가하여 150175 p/s까지 올라갔습니다 (3배 증가). 12/16 배포 후에는 감소하였고, 간헐적인 큰 스파이크가 존재하였습니다. 수신 패킷도 시간에 따라 3배 증가하는 같은 패턴이 반복되었습니다.
TO-BE
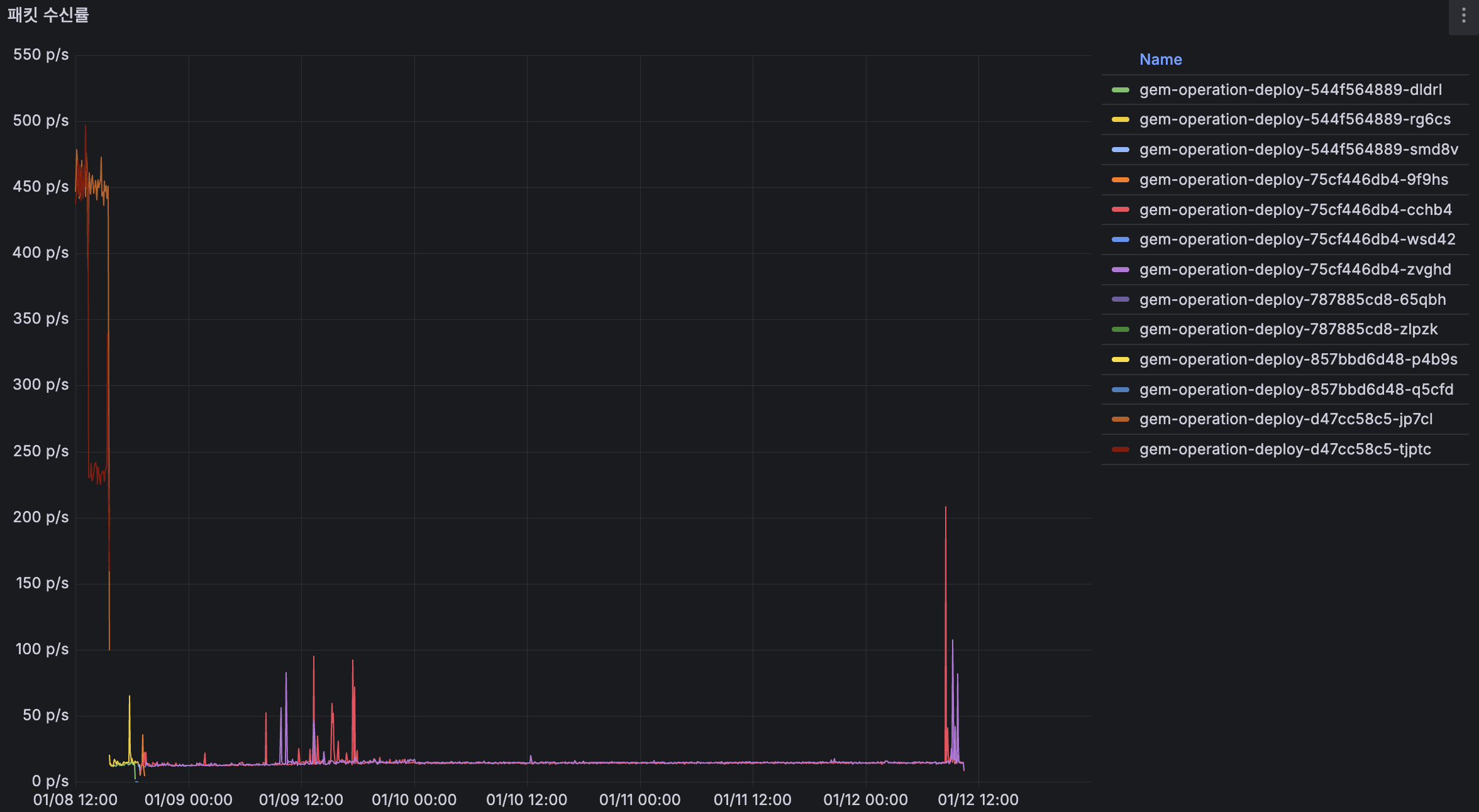
도입 이후 이전처럼 지속적으로 우상향하던 패턴이 사라지고, 최대 200p/s 수준에서 안정적으로 유지되고 있습니다.
대역폭
전송 대역폭
AS-IS
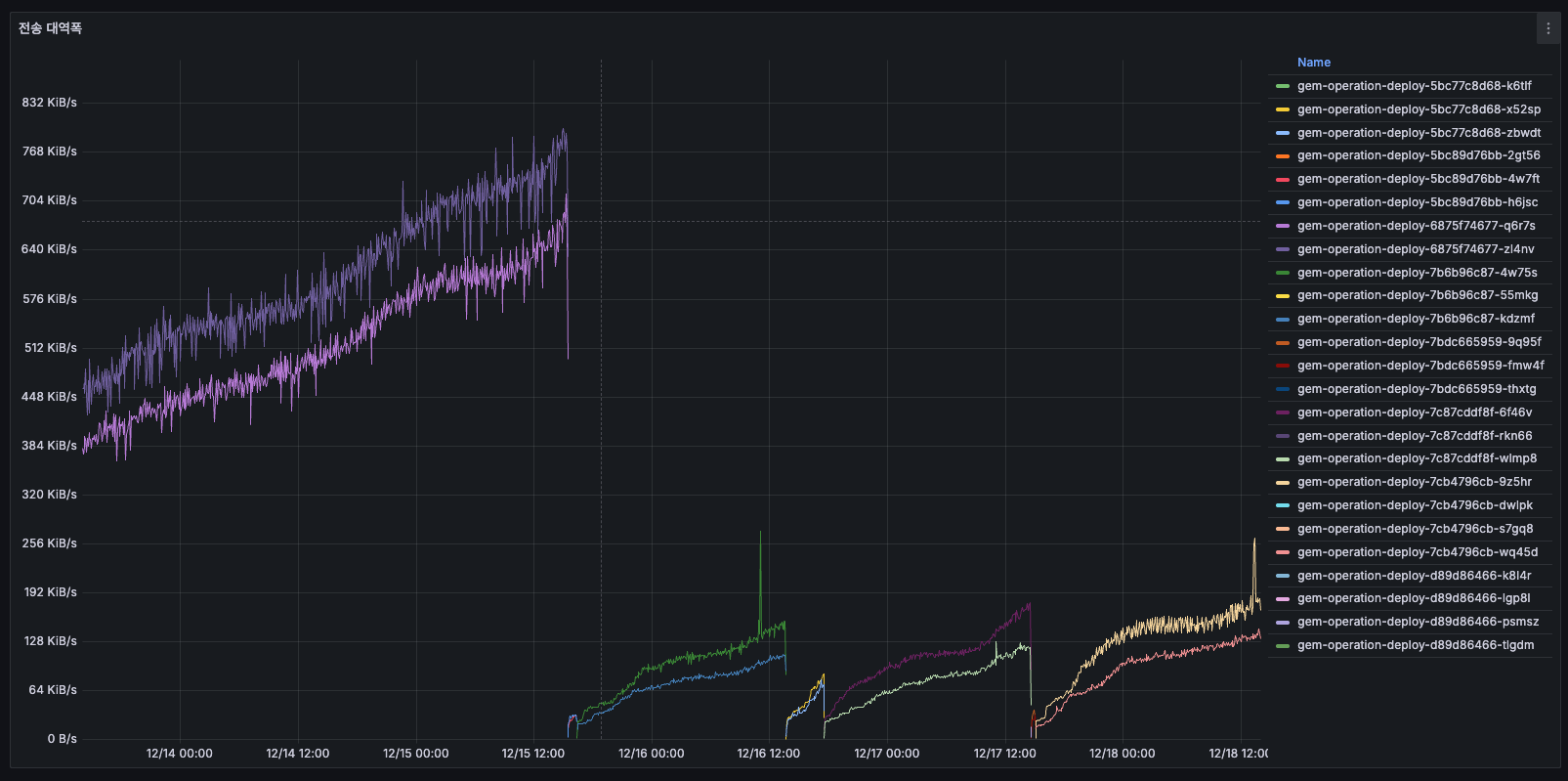
12/14 초반에는 약 384 KiB/s를 사용하고 있었고, 12/15에는 계속 증가하여 768 KiB/s 이상까지 올라갔습니다 (2배 증가). 12/16 배포 후에는 약 384 KiB/s로 리셋되었고, 이후 안정화되었습니다.
네트워크 I/O 부하가 2배 정도 증가했다가 리셋된 것으로 판단되었습니다.
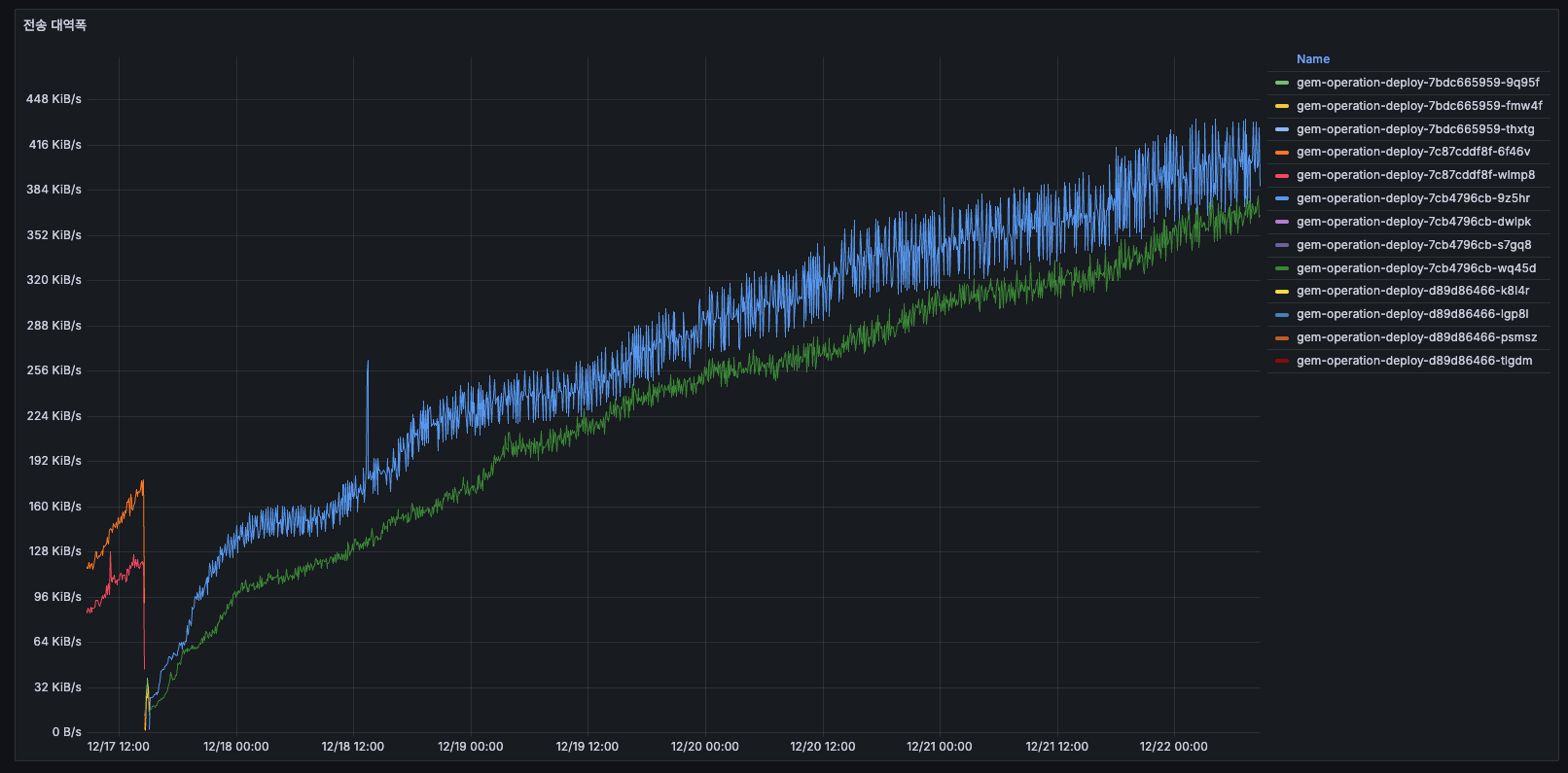
TO-BE
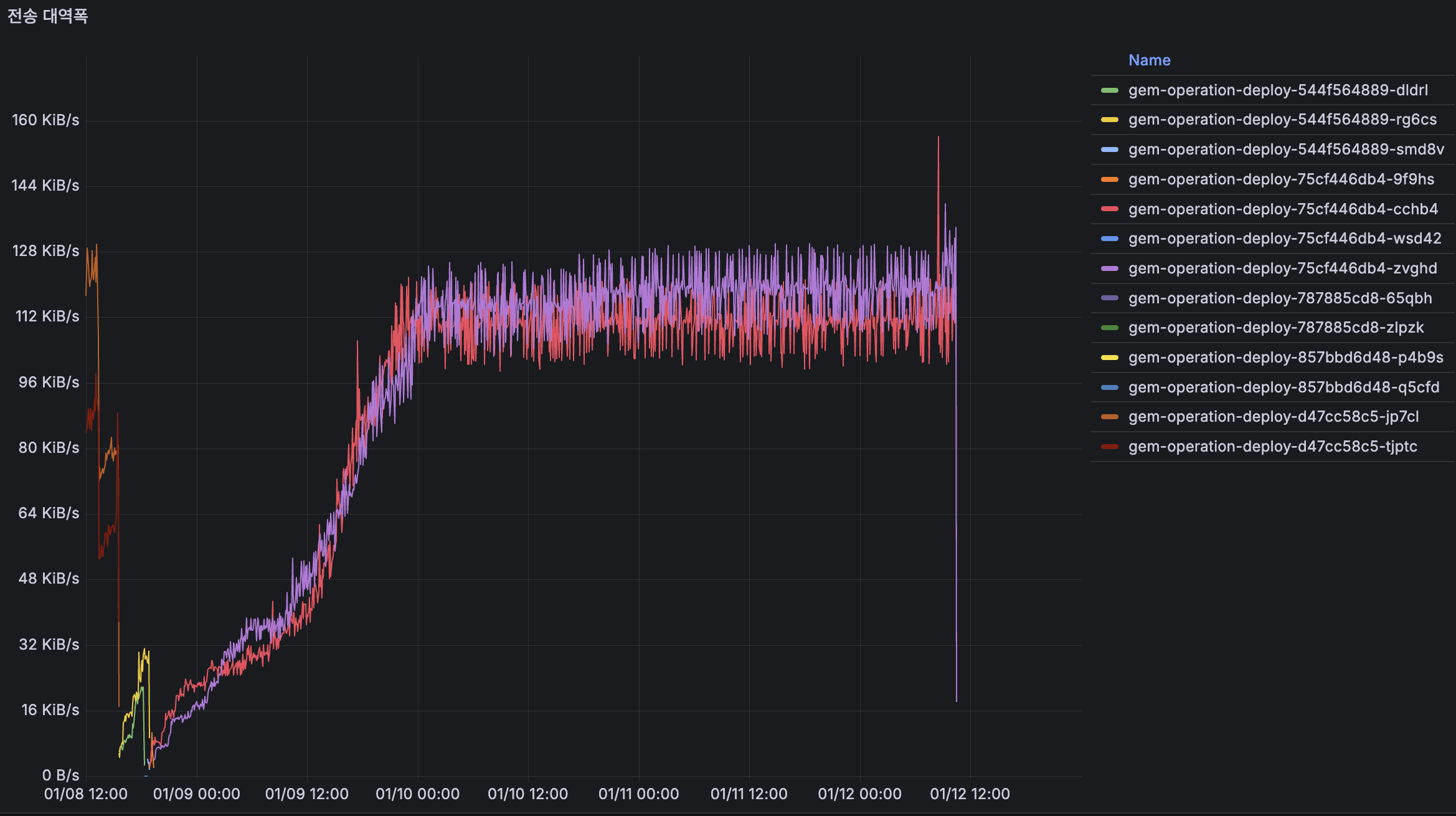
이전에 768 KiB/s 이상까지 상승하던 우상향 패턴이 사라지고, 현재는 약 126 KiB/s 수준으로 감소하여 안정적으로 유지되고 있습니다.
수신 대역폭
AS-IS
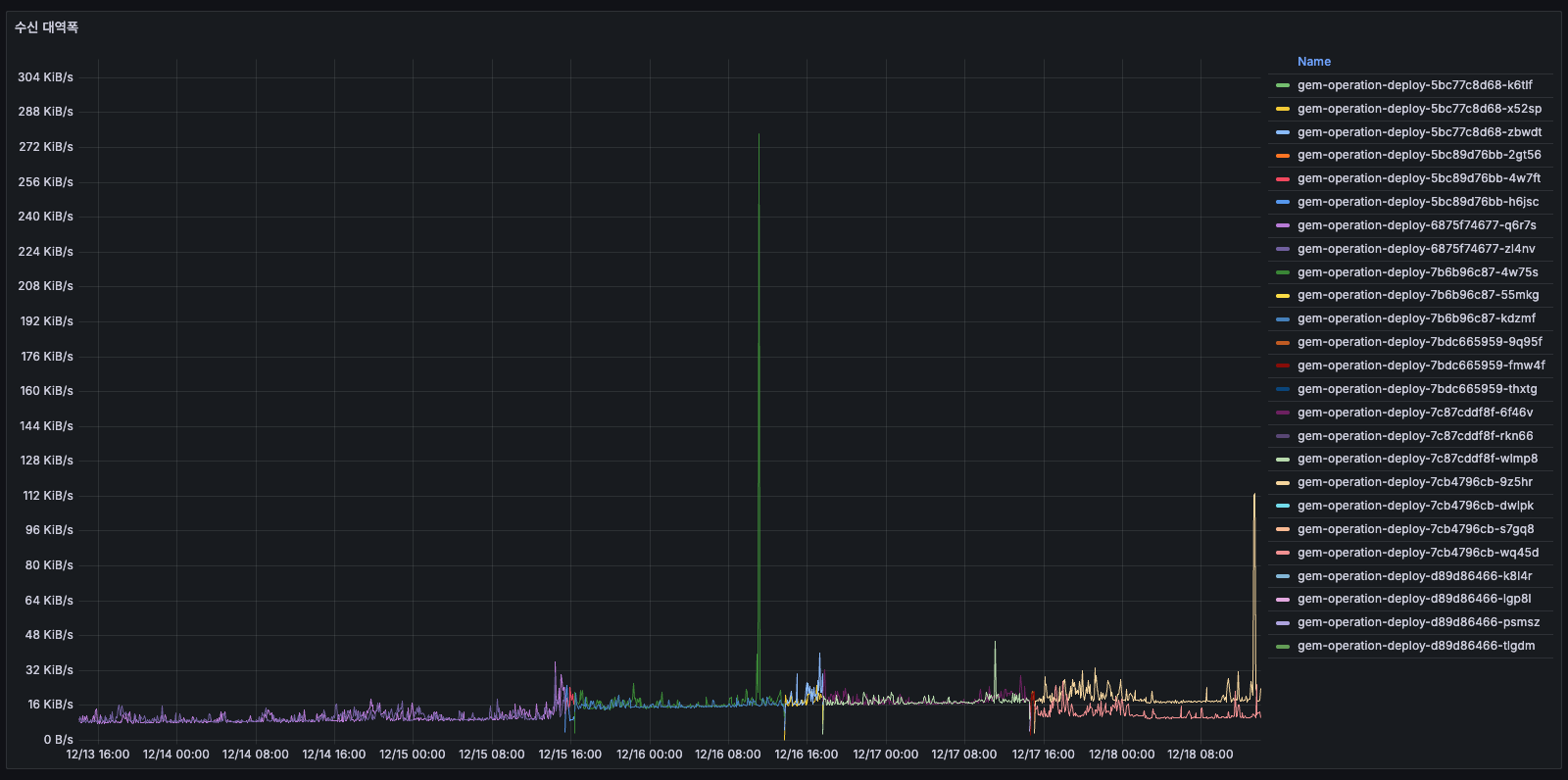
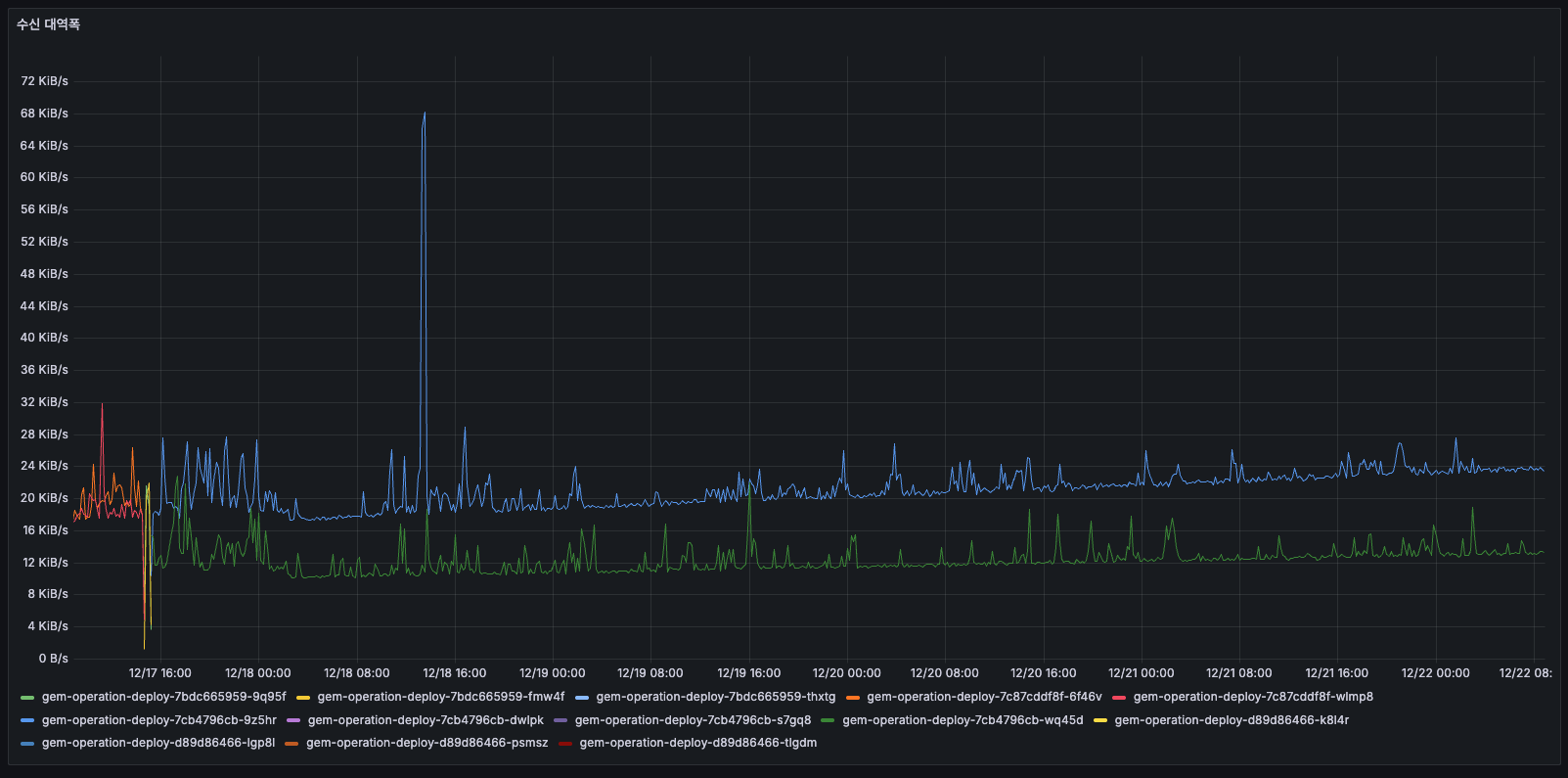
거의 0에 가까운 수준이었습니다. 구 Pod가 있을 당시에는 어느정도 데이터를 보내고 있었던 것으로 보였고, 평균의 2배를 찍고 있었으며 일정 수준 이상으로 보낼 것은 유지하고 있었으나 이후에는 0으로 떨어진 패턴을 보였습니다 (수신 없음).
보낼 것도 많았고 또한 동시에 패킷도 많았고 메모리/CPU도 증가가 원인으로 보였으므로, 결론적으로 현재 시스템에 문제가 있었고 배��로 리셋된 후에는 안정적으로 전환되었습니다.
TO-BE
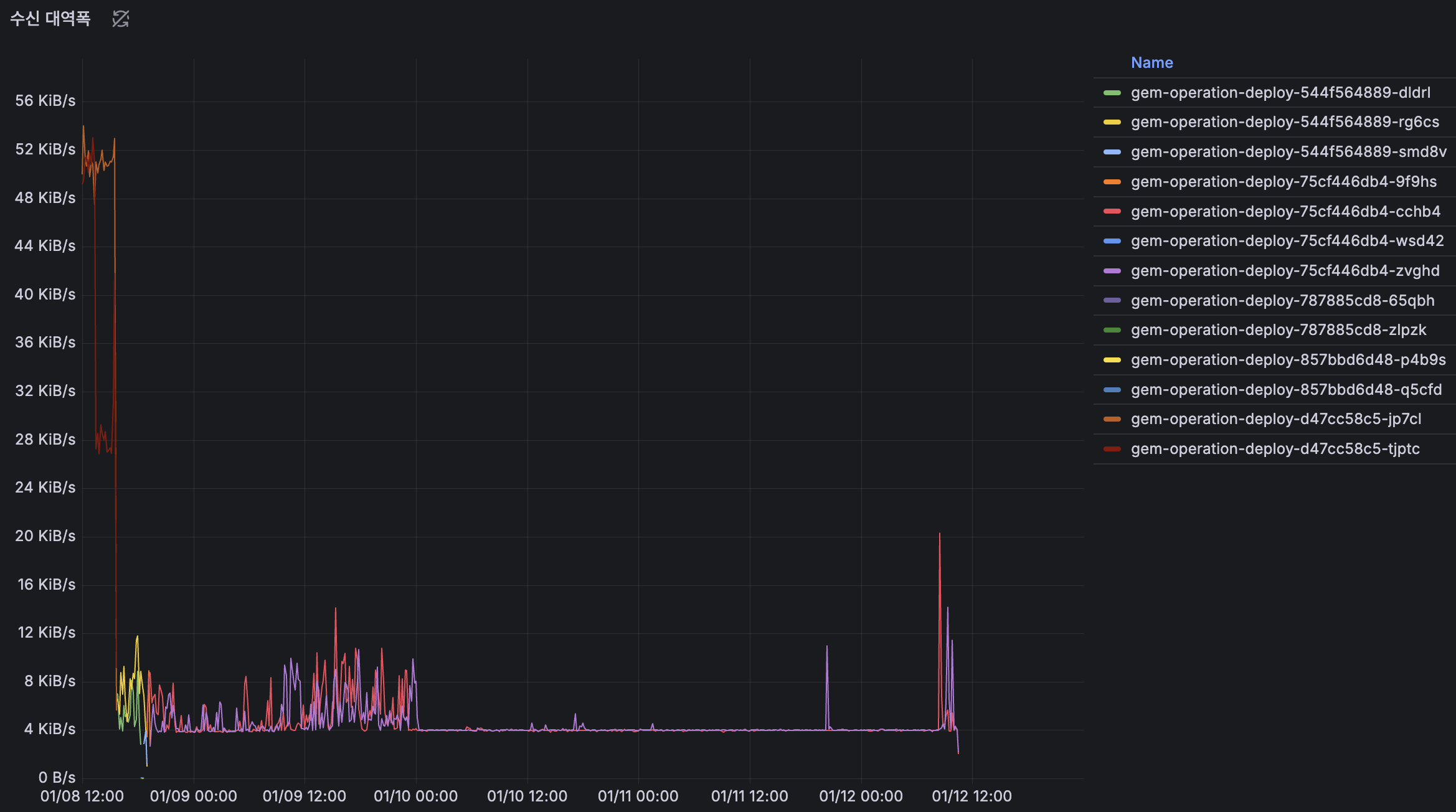
수신 대역폭은 이전과 유사한 수준을 유지하고 있으며, 트래픽 패턴이 일정하여 큰 변화 없이 안정적으로 운영되고 있습니다.
NodeJS Event Loop 지연
AS-IS
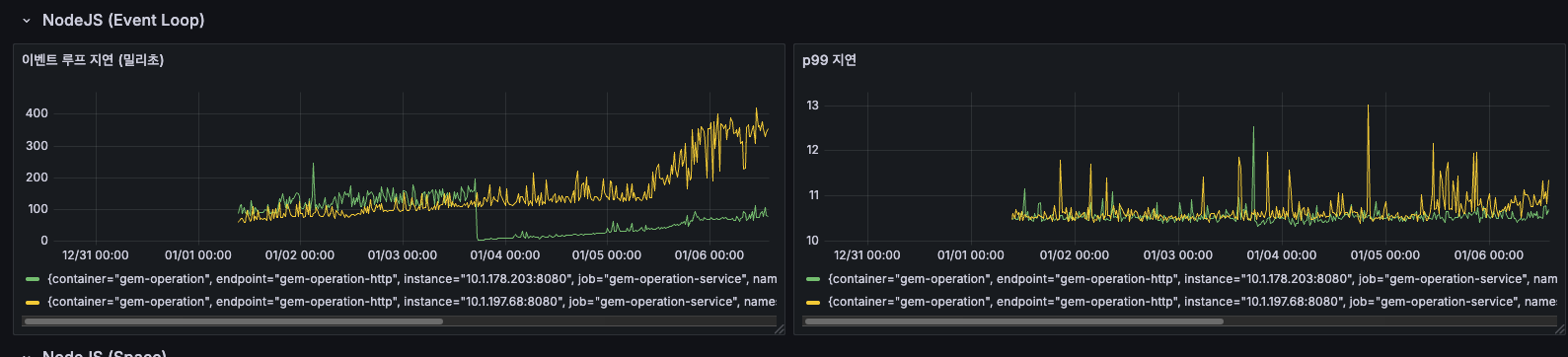
NodeJS Event Loop 지연 분석
이벤트 루프 지연 (밀리초)
12/31 ~ 01/04 기간에는 약 100150ms로 안정적으로 유지되었으나, 01/05 00:00 이후 급격히 증가하여 150250ms로 상승했고, 01/06에는 최대 400ms까지 스파이크가 발생했습니다. 특히 노란색 인스턴스에서 높은 지연이 관찰되었습니다.
이벤트 루프 지연이 급증하면 요청 처리가 지연되고 API 응답 시간이 느려집니다. 01/05 이후 급격한 증가는 특정 배치 작업이나 외부 API 호출 증가가 원인일 가능성이 있습니다.
p99 지연
전체 기간 동안 10~13ms로 매우 안정적이었고, 간헐적인 스파이크만 존재했습니다(최대 13ms). 대부분의 요청은 11ms 이내에 처리되었습니다. p99 지연은 안정적이지만, 평균 이벤트 루프 지연이 높다는 것은 일부 무거운 작업이 이벤트 루프를 블로킹하고 있다는 신호로 보입니다.
TO-BE
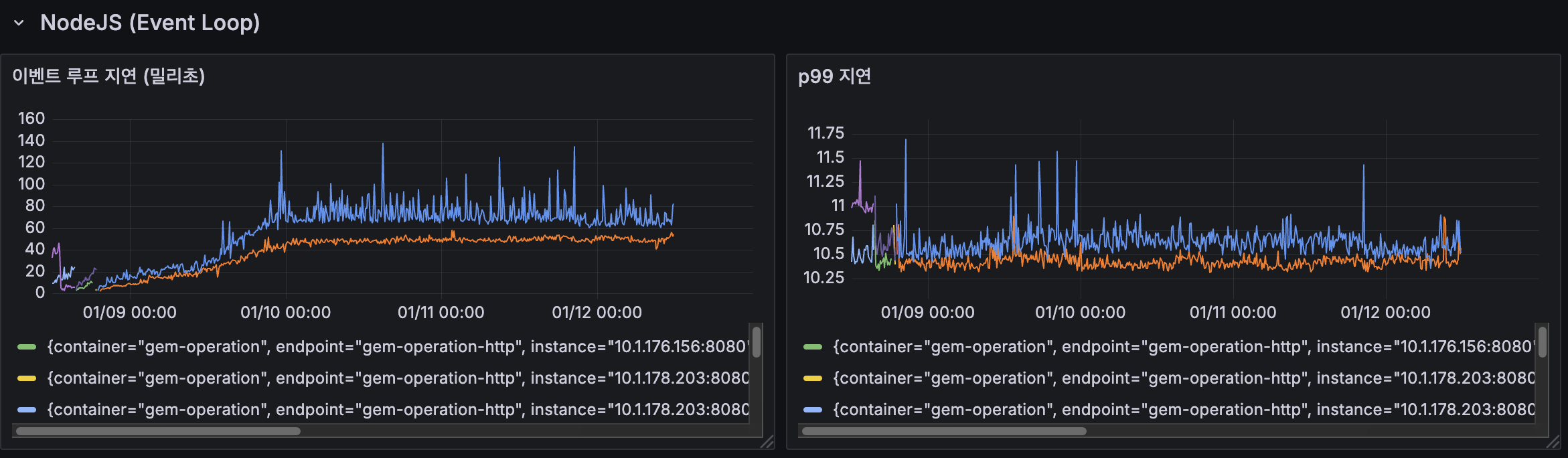
NodeJS Event Loop 지연 분석
도입 이후 이벤트 루프 지연이 개선되었습니다. 이전에 최대 400ms까지 스파이크가 발생하던 것이 현재는 약 150ms 선에서 유지되고 있으며, 최대 200ms 수준으로 상승하는 모습을 보이고 있습니다.
NodeJS Heap 메모리
AS-IS
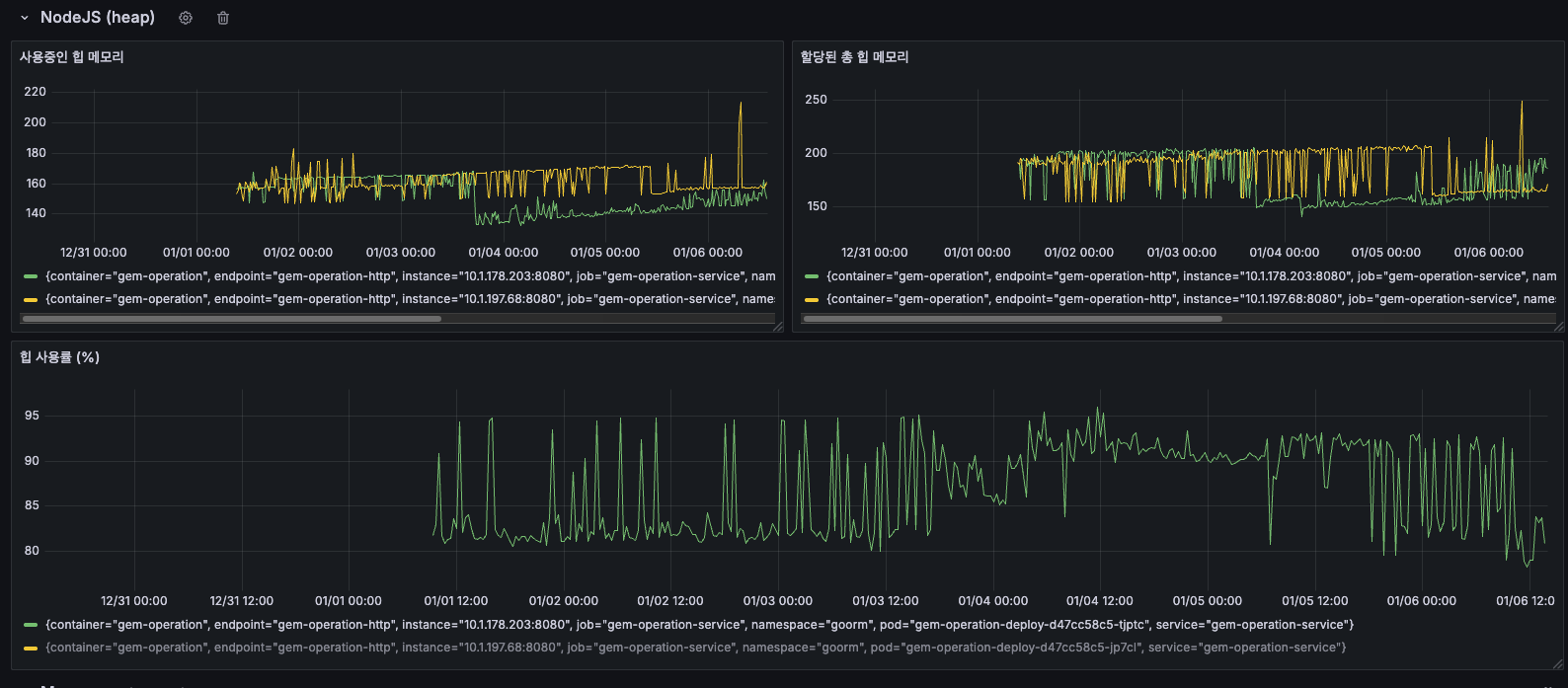
NodeJS Heap 메모리 사용 패턴
사용중인 힙 메모리
12/31 ~ 01/02 기간에는 약 150165MB로 안정적이었으나, 01/03 이후 점진적으로 상승하여 160180MB를 유지했고, 01/06에는 최대 220MB까지 스파이크가 발생했습니다. 지속적인 상승 추세가 관찰되었습니다.
할당된 총 힙 메모리
12/31 ~ 01/04 기간에는 약 150200MB 수준이었으나, 01/05 이후 200250MB로 증가했고, 01/06에는 최대 250MB까지 도달했습니다. 사용중인 힙과 유사한 패턴으로 증가했습니다.
할당된 총 힙이 증가한다는 것은 V8 엔진이 더 많은 메모리를 필요로 한다고 판단했다는 의미로, 이는 실제로 메모리 사용량이 증가하고 있음을 나타냅니다.
힙 사용률 (%)
대부분의 시간 동안 8595%를 유지했고, GC(Garbage Collection) 실행 시점에 주기적인 하락 패턴이 나타났습니다. 01/01 이후에는 8095% 사이에서 톱니 패턴이 반복되었습니다.
85%가 많아보일 수 있지만, 전체 최대 힙 크기는 4096MB 이상이기 때문에 장애가 나는 수준이 절대 아니고, 오히려 넉넉한 편입니다. 할당된 총 힙 메모리는 NodeJS 앱의 할당된 총 힙 메모리가 아닌, 그 시점에 OS로부터 할당받은 메모리이기 때문에 전체 사용량을 절대 넘어서지 않습니다.
TO-BE
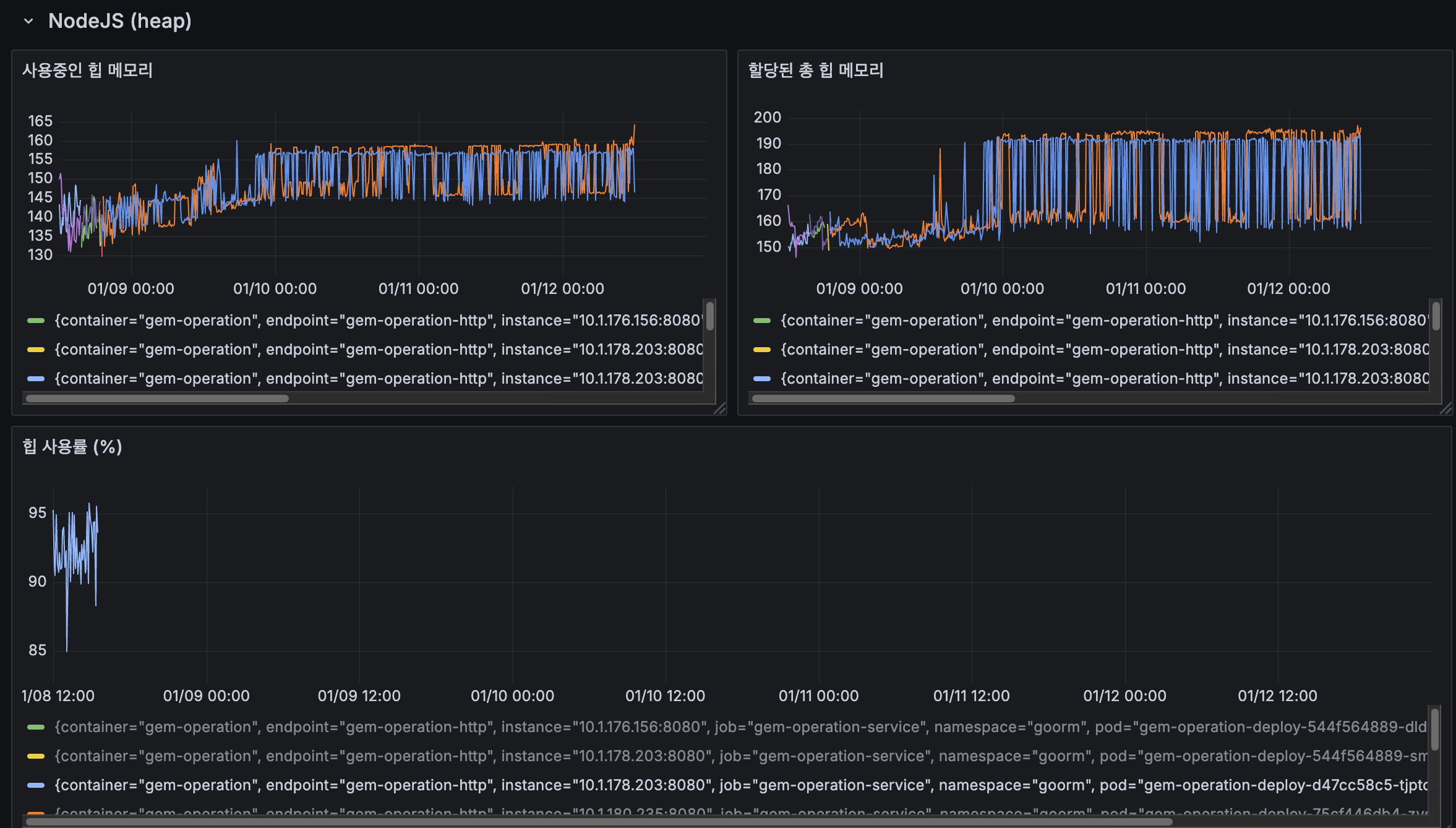
NodeJS Heap 메모리 사용 패턴
도입 이후 힙 메모리 사용 패턴은 이전과 유사한 수준을 보이고 있습니다. 사용중인 힙 메모리와 할당된 총 힙 메모리가 이전과 비슷한 범위에서 유지되고 있으며, 힙 사용률도 85~95% 수준에서 GC 실행 시점에 주기적인 하락 패턴을 보이고 있습니다. 큐 개선만으로는 힙 메모리 사용 패턴에 큰 변화가 없었던 것으로 보입니다.
NodeJS Space
AS-IS
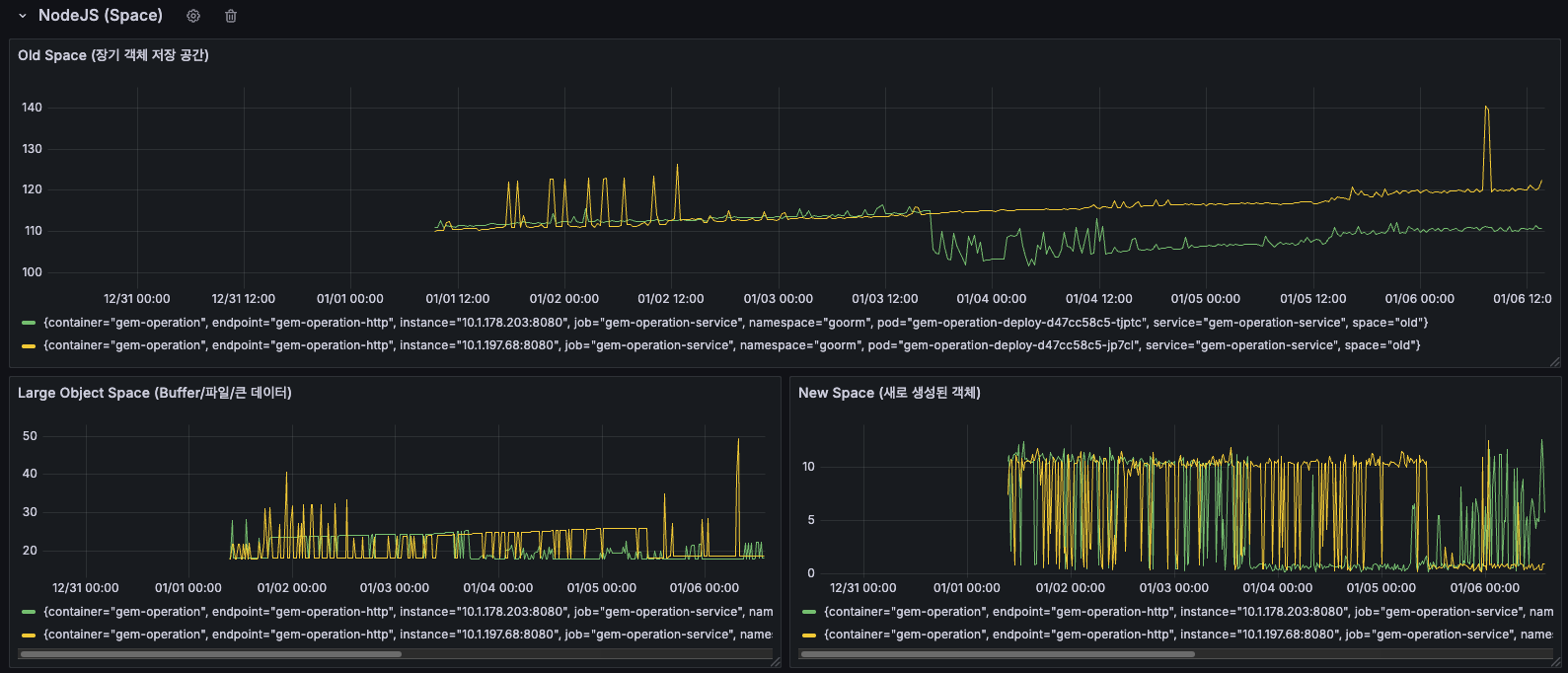
NodeJS Space 메모리 영역별 사용 현황
New Space Size (Young Generation)
전체 기간 동안 주기적인 톱니 패턴이 반복되었으나, 01/05 이후 스파이크가 더 자주 발생하고 피크 값이 증가했습니다. 01/06 시점에는 급격한 스파이크가 확인되었습니다.
New Space는 새로 생성된 객체들이 할당되는 영역입니다. 주기적인 톱니 패턴은 Minor GC(Scavenge)가 정상적으로 작동하고 있다는 의미이지만, 스파이크가 증가한다는 것은 새로운 객체 생성이 급증했다는 신호입니다.
Old Space Size (Old Generation)
12/31 ~ 01/04 기간에는 비교적 안정적이었으나, 01/05 이후 점진적 증가 추세를 보였습니다. 여러 메트릭들이 시간에 따라 증가하는 패턴이 확인되었습니다.
Old Space는 Minor GC에서 살아남은 장수 객체들이 이동하는 영역입니다. Old Space가 지속적으로 증가한다는 것은 메모리에서 해제되지 않는 객체들이 계속 누적되고 있다는 의미로, 메모리 누수의 강력한 증거로 보입니다.
TO-BE
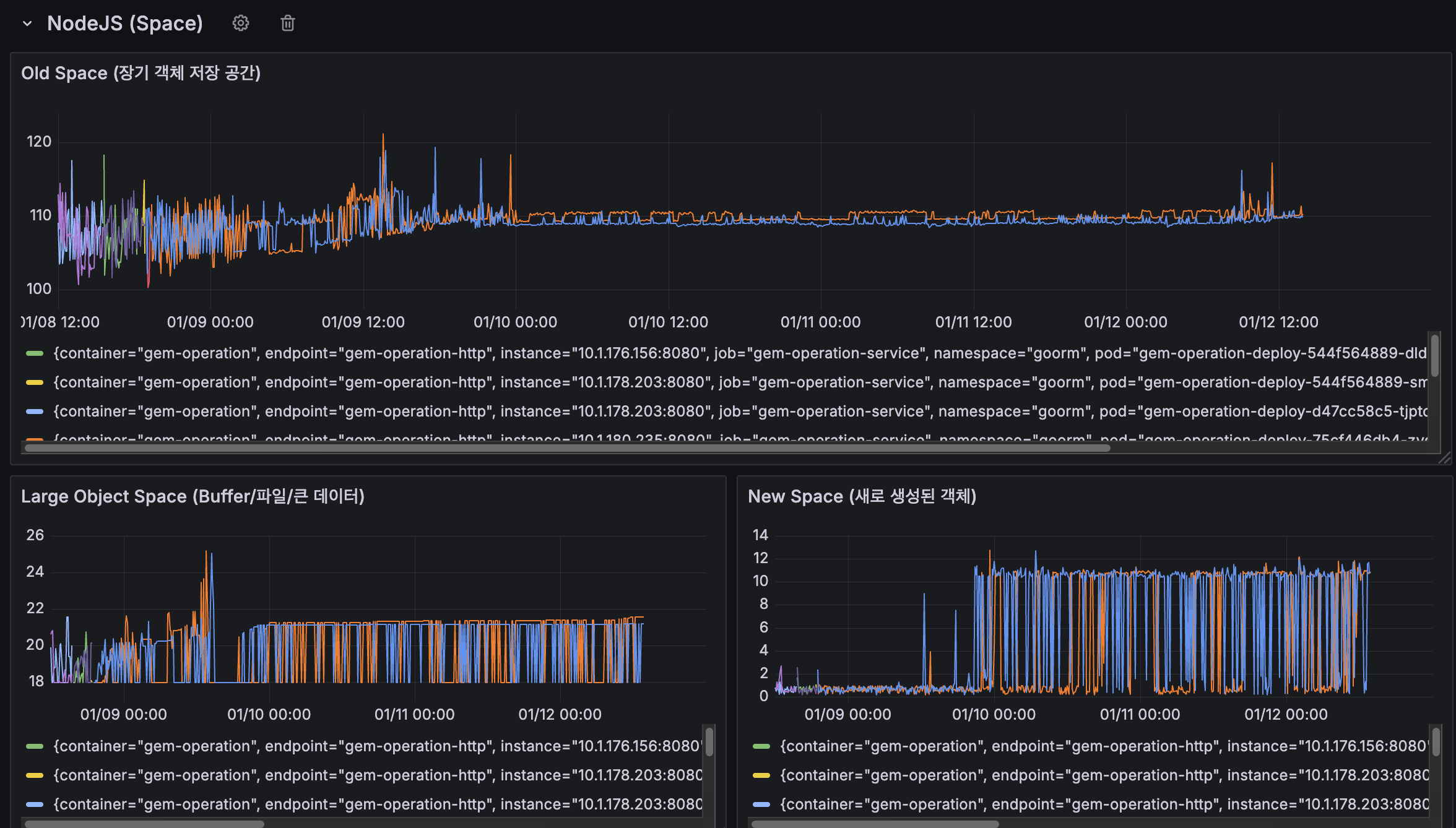
NodeJS Space 메모리 영역별 사용 현황
New Space Size (Young Generation)
도입 이후에도 전체 기간 동안 주기적인 톱니 패턴이 정상적으로 유지되고 있습니다. 01/10 이후 일부 인스턴스에서 스파이크가 12~13까지 더 자주 발생하는 모습이 관찰되지만, Minor GC(Scavenge)가 정상적으로 작동하고 있어 New Space는 안정적인 상태를 보이고 있습니다.
Old Space Size (Old Generation)
01/08 ~ 01/10 초반 기간에는 105115MB 사이에서 스파이크가 발생했고, 특히 01/09 12:00 시점에 일부 인스턴스가 120MB까지 상승하기도 했습니다. 그러나 01/10 이후로는 더 안정적인 패턴을 보이며, 약 108112MB 사이에서 유지되고 있습니다. 이전에 지속적으로 증가하던 추세가 사라지고 안정화된 것으로 보입니다.
Large Object Space
01/09 초반에 2526MB까지 스파이크가 발생했으나, 이후 1822MB 사이로 안정화되었습니다. 큰 객체 공간도 이전과 비교하여 더 안정적인 패턴을 보이고 있습니다.
이전에 Old Space가 지속적으로 증가하며 메모리 누수 증거로 보였던 패턴이, 도입 이후 안정화되고 스파이크가 줄어든 것으로 보아 큐 개선이 메모리 관리에 긍정적인 영향을 미친 것으로 판단됩니다.
3. 기술 운영
기술 운영 측면에서 이번 프로젝트를 평가해보면, 세 가지 기준으로 나누어 살펴볼 수 있습니다.
장애 대응
이번 큐 시스템 개선 작업에서는 장애 대응 측면에서 몇 가지를 준비했습니다.
먼저, 이전 글에서 살펴본 에러 처리 플로우를 통해 복구 가능한 에러와 불가능한 에러를 구분하고, Dead Letter Queue에 저장하여 7일 후 재시도하도록 설계했습니다. 또한 에러 발생 시 Slack 알림을 통해 빠르게 감지할 수 있도록 했습니다.
하지만 모니터링과 알림 측면에서는 아직 부족한 부분이 있었습니다. 이번 프로젝트에서는 성능 지표(메모리, CPU, 네트워크 등)를 측정하고 분석했지만, 실시간으로 이러한 지표를 모니터링하고 임계값을 넘어설 때 알림을 받는 자동화된 시스템은 구축하지 못했습니다. Grafana나 Elastic Search Watcher 같은 도구를 활용한 모니터링 시스템 구축은 다음 단계 과제로 남겨두었습니다.
또한 Fault Injection을 통한 장애 시나리오 테스트나, 실제 장애 상황에서의 대응 프로세스 검증은 이번 프로젝트에서 다루지 못했습니다. 이는 향후 개선이 필요한 부분입니다.
재발 방지
재발 방지 측면에서는 에러 처리 플로우를 통해 몇 가지 장치를 마련했습니다. 이전 글에서 구현한 에러 처리 플로우를 통해, 복구 가능한 에러(INVALID_CREDENTIAL, EXPIRED_CREDENTIAL 등)와 불가능한 에러를 구분하고, 복구 가능한 에러는 Dead Letter Queue에 저장하여 7일 후 자동 재시도하도록 설계했습니다. 이를 통해 일시적인 네트워크 오류나 인증 만료 같은 문제로 인한 실패가 자동으로 복구될 수 있도록 했습니다.
또한 모든 에러 발생 시 SheetTransaction을 FAILED 상태로 저장하여 에러 이력을 추적할 수 있도록 했고, Redis Key를 삭제하여 중복 처리를 방지했습니다. 에러 발생 시 상세한 로그를 남기고 Slack 알림을 통해 빠르게 감지할 수 있도록 했습니다. 이러한 설계를 통해 동일한 에러가 반복 발생하더라도 추적하고 분석할 수 있는 기반을 마련했습니다.
성능 지표 측면에서는 메모리 누수 문제를 발견하고, Old Space가 지속적으로 증가하는 패턴을 확인하여 메모리 누수의 강력한 증거를 찾아냈습니다. 또한 도입 이후 이러한 패턴이 안정화되는 것을 확인하여, 큐 개선이 메모리 관리에 긍정적인 영향을 미쳤음을 검증했습니다.
하지만 Root Cause 분석 측면에서는 아직 깊이 있는 분석이 부족했습니다. 메모리 누수의 정확한 원인을 코드 레벨에서 추적하거나, 힙 스냅샷을 분석하여 어떤 객체가 누수되고 있는지 구체적으로 파악하지는 못했습니다. 단순히 큐 개선으로 문제가 해결된 것으로 보이지만, 근본 원인에 대한 분석은 더 깊이 있게 진행할 필요가 있습니다.
지속적 개선
지속적 개선 측면에서는 성능 최적화를 위해 지표를 측정하고 분석한 점이 긍정적이었습니다. 메모리, CPU, 네트워크, NodeJS 성능 지표 등 다양한 지표를 측정하여 개선 전후를 비교하고, 실제 임팩트를 확인했습니다.
하지만 운영 자동화 측면에서는 아직 부족한 부분이 많습니다. 큐를 통한 자동 복구 실행은 구현했지만, 결국 credential을 사람이 직접 갱신해줘야 한다는 점에서 어느정도 수동인 부분이 남아있어 이러한 한계는 넘어서지 못한 것 같습니다.
또한 이번 프로젝트를 통해 얻은 인사이트를 바탕으로, 향후 아키텍처 진화나 사업 확장에 대응할 수 있는 방안을 고민해야 할 것 같습니다. 현재는 큐 시스템 개선에 집중했지만, 더 큰 관점에서 시스템 전체를 바라보고 개선해보면 좋을 것 같아요.
4. 제품과 비즈니스
이번 프로젝트를 통해 제품의 규모를 정확히 파악하고 그에 맞는 설계를 선택하는 것이 비즈니스 성장에 직접적으로 영향을 미친다는 것을 배웠습니다. 단순히 최신 기술을 도입하는 것이 아니라, 제품의 특성과 규모를 정확히 이해하고 그에 맞는 최적의 설계를 찾아나가는 것이 내가 있을 때와 없을 때의 차이를 만드는 핵심이라고 생각합니다.
제품 규모에 맞는 설계 선택
우리의 작고 귀여운 트래픽
항상 개선을 할 때 부하 테스트 등을 통해서 큰 데이터가 있을 때, 그리고 엄청난 트래픽이 있을 때도 버티는 좋은 아키텍처만을 사용하는 것이 중요하다고 생각했었습니다. 하지만 이번 작업을 통해서는 조금 더 다르게 생각해보게 되었습니다.
예를들어 엔터프라이즈급 대기업이 운영하는 제품들이 Kafka를 도입하고 있는데, 과연 Kafka를 우리 수준의 트래픽에 도입하는 것이 맞을지에 대해서 항상 치열하게 고민하고 연구하고 실험해봐야 하겠더라고요. 왜냐하면 오버엔지니어링과 언더엔지니어링을 구분하는 것이 좋은 개발자의 관점이고, 이를 빠르게 파악하고 빠르게 도입하고 실패하고 좋은 설계를 찾아나가는 것이 좋은 개발자라고 생각이 들었기 때문입니다. 지금 2~3년차를 향해 나아가는 순간에 가장 중요한 스킬셋이고 더 성숙해져야 하는 부분이라고 보고있습니다.
우리 제품은 사실 인터널 제품이면서, 익스터널한 제품이기도 합니다. 익스터널한 부분은 지원자나 사용자가 설문조사나 지원서를 작성하는 부분이고, 인터널한 부분은 사내 구성원들이 이러한 지원서를 만들고 작성하는 부분입니다. 구글폼과 같이 어드민과 사용자 익스터널 서비스가 같이 있는 꼴인데, 사실 따져보면 그렇게 트래픽이 크지 않습니다.
이러한 관점에서 메타인지가 잘 되고 트래픽을 먼저 살펴보고, 그에 따라서 설계를 선택한 것이 좋은 경험이었습니다. 왜냐하면 대용량 트래픽일 경우 큐를 돌릴 때 무조건 배치성으로 작업했어야 하는데, 사실 우리 트래픽 수준에서는 배치성에서 나오는 단점(즉시 반영 안됨)을 포기할 만큼 트래픽이 있지 않기 때문에 그러한 단점을 상쇄하고 장점을 가져갈 것을 챙기는 것이 좋았습니다. 결국 이러한 고민을 통해 좋은 설계가 나왔던 것 같습니다.
비즈니스 성장에 기여
나의 제품의 규모를 잘 알고 있고, 비즈니스적으로도 더 성장하도록 만들었다고 생각해요.
이전에 시트에 대한 추적이 안되었을 때는 지원자에 대한 누락이 생기기 마련이었는데, 이러한 문제는 개발단에서도 모르고 운영단에서도 모르기 때문에 블랙박스였습니다 (정말 부끄럽게도 사실입니다).
이 지원자 한 명 한 명이 매출의 큰 부분을 차지하기 때문에 데이터를 동기화하고 트래킹하는 것은 이 사업에 대해서 가장 중요한 부분이거든요. 그래서 제가 한 안정화 작업은 기술적인 개선도 있지만 무엇보다 사업적으로 더 안정적이고 올바른 시스템을 구축했다는 점에서 의미가 있다고 생각합니다.
이전에는 지원자 데이터가 누락되어도 알 수 없었��만, 이제는 에러 발생 시 SheetTransaction을 통해 추적할 수 있고, Dead Letter Queue를 통해 재시도할 수 있어 데이터 누락을 방지할 수 있게 되었습니다. 블랙박스였던 시스템이 이제는 조금은 더 투명하게 추적 가능한 시스템으로 변화했습니다.
5. 커뮤니케이션
이번 프로젝트를 통해 커뮤니케이션 측면에서 중요한 교훈을 얻었습니다.
데이터 기반 설득
상위 리더에게 이 프로젝트의 필요성을 설득할 때, 데이터 기반으로 접근했습니다. 이전 글에서 나온 데이터 분석을 업무 외 시간에 사이드 프로젝트로 먼저 진행하고, 우리 서버에 대한 데이터와 지표, 문제점을 정리해서 문서로 전달했습니다. 어쩌면 POC(Proof of Concept)와 같은 부분이었습니다.
사업적인 임팩트가 없으면 윗선에서 리젝당하기 마련인데, 이러한 기술적인 부분과 사업적인 부분을 모두 챙기는 작업을 하는 것이 좋은 것 같습니다. 가끔 개발자들이 실수하는 것이 사업적인 맥락을 놓치고 개발적인 개선에만 집중하는 경우들이 있는 것 같고, 저도 항상 그랬던 것 같습니다.
클린코드나 구조 같은 경우 매우 중요하긴 한데, 당장 사업팀 입장에서는 달라지는 기능이 없어서 크게 와닿지 않을 수 있거든요. 이러한 구조 개선이나 기술적인 부분들에 대한 리소스 투여를 설득하려면 어느 정도 사업적인 임팩트가 필요한 것 같습니다.
개발로 하여금 사업적인 임팩트를 내려면 무엇이 있을까 생각해보면 새로운 기능, 아니면 안정성이라고 생각해요. 이번 프로젝트에서는 안정성을 많이 강조했고, 그 근거로 데이터 지표를 많이 활용했습니다. CS 또한 관련 내용으로 많이 들어오고 있었던지라, 상위 리더도 인지하고 있었기 때문에 설득할 수 있었습니다.
모든 맥락을 아는 팀원들 사이에서는 가정만으로 효과를 볼때도 있지만, 맥락을 아예 모르는 사람 입장에서는 가정만으로는 설득이 되지 않더라고요. 그래서 데이터로 방향성을 제시하는 것이 중요하기에 먼저 데이터를 수집하고 분석하여 문제점을 명확히 파악한 후, 이를 바탕으로 프로젝트의 필요성을 설득하는 것이 훨씬 효과적이었습니다.
문서화를 통한 문맥 전달
프로젝트 도입 제안을 위한 규격화되어있던 문서
이번 프로젝트에서는 위와 같은 마일스톤 문서와 함께 이전 글과 같은 내용의 노션 문서를 통해 데이터 분석 결과를 정리하여 전달했습니다. 단순히 말로 전달하는 것이 아니라, 지표와 그래프를 포함한 문서를 통해 문제점과 개선 방향을 명확히 전달할 수 있었습니다. 그래서 기록을 통해 문맥을 명확히 전달하는 것이 중요하다는 것을 배웠습니다.
또한 피드백도 기록하는 것이 좋았던 것 같아요. 이러한 문서를 통해 상위 리더분께서 좀 더 사용성 측면에서 확장하는 방향들을 제안해주셨어요. 예를 들어 시트 동기화가 성공하면 관리자에게 알림을 주거나, 현황 대시보드에 추가하여 비개발자 관리자들도 활용할 수 있게 하는 것 등이 있었습니다.
시트 동기화 실패 상태
시트 명시적인 동기화 기능
이러한 피드백을 바탕으로 대시보드에 시트 관련 동기화 여부와 동기화할 수 있는 버튼을 추가했습니다.
이전 포스트들에는 기술적으로 설명할 내용이 없어서 제외해두었는데, 사실 비즈니스적으로 그리고 사용자들이 크게 와닿는 부분이라서 꽤 중요한 부분이라고 생각해요. 기술적인 구현보다는 사용자 경험과 비즈니스 가치에 더 가까운 부분이지만, 이런 부분이 오히려 더 큰 임팩트를 만들 수 있다는 것을 배웠습니다.
마지막으로 최근성 효과(Recency effect)에 대한 글들도 최근에 접하고 있었습니다. 이를 활용하여 적절한 시점에 문서를 공유하는 것도 큰 역할을 했다고 생각합니다.
구체적으로는 문제가 발생한 CS가 제보되었을 때처럼, 프로젝트의 필요성을 상위 리더가 직접 느낄 수 있는 최근 시점에 문서를 공유하는 것이 효과적이었습니다. 최근에 경험한 문제와 연결된 시점에 제안을 전달하니 더 큰 공감을 얻을 수 있었던 것 같습니다.
6. 마치며
이번 프로젝트를 통해 기술 운영, 제품과 비즈니스, 커뮤니케이션 세 가지 축으로 나누어 스스로를 평가해보았습니다. 솔직히 말하면, 각 영역에서 부족한 점이 많았어요. 모니터링 자동화도 제대로 구축하지 못했고, Root Cause 분석도 더 명확하게 하지 못했고, 운영 자동화도 아직 많이 부족합니다.
하지만 이번 프로젝트를 통해 정말 많이 배웠고, 조금 달려봤다고 생각해요.
이전에는 그냥 설계하고 구현하고 끝내는 프로세스였습니다. 이번에는 다르게 접근해봤습니다. 먼저 데이터를 수집하고 분석해서 문제점을 파악하고, 그 다음에 설계하고 구현하고, 그리고 나서 다시 지표를 측정해서 실제로 개선되었는지 확인하고, 마지막으로 이렇게 회고까지 남겨보는 등의 훨씬 더 심층적인 프로세스를 통해 업무를 해보았습니다.
단순히 코드만 잘 짜는 게 아니라, 제품의 규모를 이해하고 사업적인 맥락을 고려하고, 데이터로 설득하고, 지속적으로 측정하고 개선하는 등 전체적인 프로세스를 이해하고 실행하는 게 개발자로서 일하는 방식의 정답에 가깝지 않을까 싶었습니다.
그래서 이렇게 일해야겠구나를 조금은 깨닫고 팀원들에게도 같이 이렇게 하자고 어필해봤던 것 같아요.
물론 아직 많이 부족하다 생각하고 성장할 부분들이 많아요! 하지만 이번 프로젝트를 통해 부족한 부분을 명확히 알 수 있었고, 앞으로 어떤 방향으로 성장해야 할지도 보였습니다.
소프트 스킬의 중요성도 정말 크게 느꼈어요. 기술적인 개선만으로는 부족하고, 커뮤니케이션이 엄청 중요하더라고요. 데이터를 기반으로 의견을 조율하고 협의할 수 있는 능력, 이것도 훈련을 통해 키워나가야 할 것 같습니다.
그리고 매 프로젝트마다 이런 회고를 남겨두면, 나중에 비슷한 선택의 기로에 섰을 때 예전의 나를 떠올리며 그때는 이렇게 생각했고, 지금은 어디까지 왔는가를 비교해볼 수 있을 것 같아서 앞으로도 똑같은 프로세스로 프로젝트를 진행하려고 합니다. (이전 프로젝트에 안했던 것이 굉장히 후회가 됩니다. 지금부터라도 해보려고 해요.)
지금 2~3년차를 향해 나아가는 순간에, 계속 스스로를 점검하고 나아가며 일을 잘하는 엔지니어로 성장하고 싶습니다. 부족하지만, 달려봤고, 성장했고, 앞으로도 더 많이 노력하면서 나아가려고 합니다!