N+1 쿼리 최적화와 Connection Pool 튜닝으로 해결한 Connection Timeout 문제
HikariCP 대시보드에서 Connection Timeout이 27회 발생하는 문제를 발견했습니다. 원인은 N+1 쿼리 문제와 작은 Connection Pool 크기였습니다. 배치 조회로 N+1 쿼리를 해결하고 Connection Pool 크기를 5에서 20으로 증가시켜 Timeout을 0으로 만들었습니다. 쿼리 수는 161개에서 3개로 98% 감소했습니다.
들어가며
“Connection Timeout Count: 27”
HikariCP 대시보드를 보던 중 이 숫자를 발견했습니다. 27번의 Connection Timeout이 발생했다는 의미였죠. 사용자 요청이 실패하고 있었을 가능성이 높았습니다.
대시보드를 자세히 살펴보니 더 심각한 문제들이 보였습니다:
- Connection Creation Time이 4.5초까지 치솟음
- Connection Acquire Time이 5-6초까지 증가
- Connection Usage Time이 450ms로 높게 유지
- Pending connections가 최대 5-7개까지 증가
이런 상황에서 사용자 경험은 어떨까요? API 응답이 느리고, 때로는 타임아웃으로 실패할 수 있습니다.
이번 글에서는 이 문제를 해결하기 위해 N+1 쿼리 문제를 배치 조회로 최적화하고, Connection Pool 크기를 조정한 과정을 공유합니다.
문제 분석
1. HikariCP 대시보드 분석
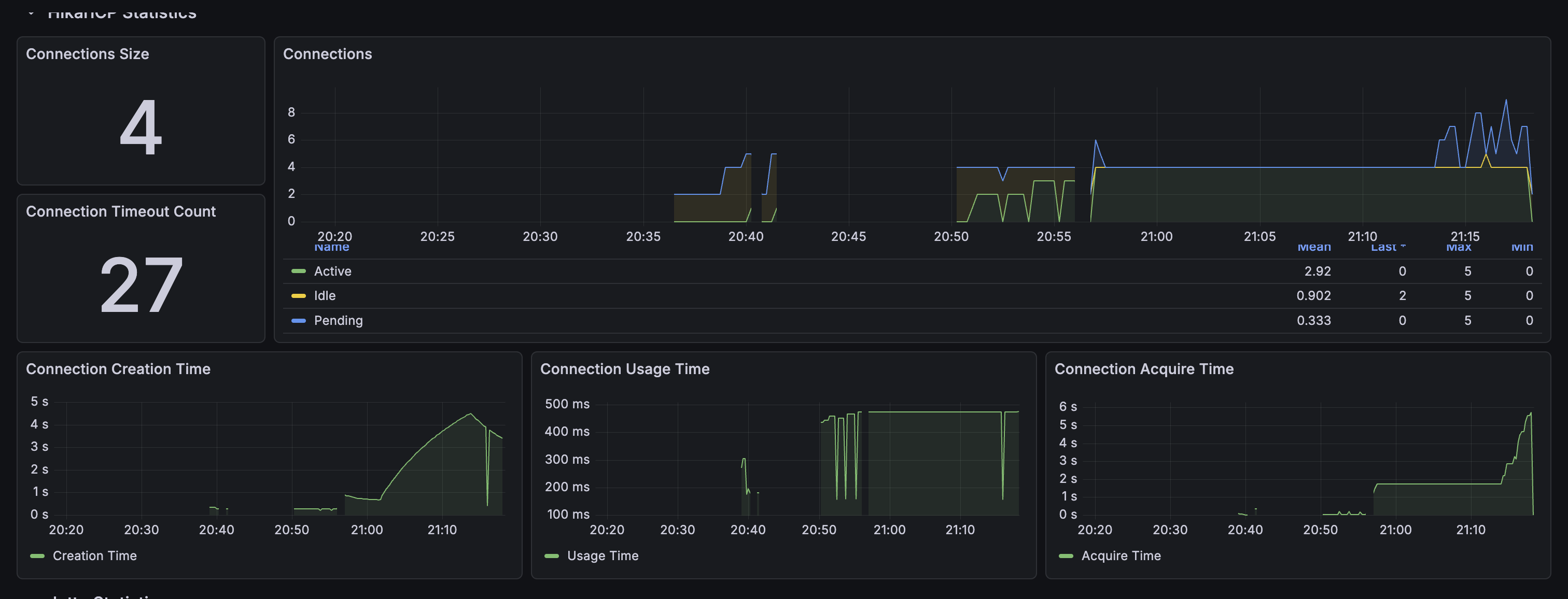
대시보드를 통해 확인한 주요 문제점들:
Connection Timeout 현황:
- Connection Timeout Count: 27회
- Connection Creation Time: 최대 4.5초
- Connection Acquire Time: 최대 5-6초
- Connection Usage Time: 평균 450ms
Connection Pool 상태:
- Maximum Pool Size: 5개 (너무 작음)
- Active Connections: 최대 4-5개
- Pending Connections: 최대 5-7개 (Pool 크기 초과)
2. 코드 분석: N+1 쿼리 문제 발견
문제의 핵심은 getSessionsWithFiles 메서드에 있었습니다:
override fun getSessionsWithFiles(
sessions: List<ClassSession>,
organizationId: OrganizationId,
): List<ClassSessionWithFiles> {
return sessions.map { session ->
// 각 세션마다 개별 쿼리 실행 (N+1 문제!)
val planFile = session.planFileId?.let {
fileRepository.findById(it, organizationId) // 쿼리 1
}
val reportFile = session.reportFileId?.let {
fileRepository.findById(it, organizationId) // 쿼리 2
}
val classVideoFile = session.classVideoFileId?.let {
fileRepository.findById(it, organizationId) // 쿼리 3
}
val summaryDocumentFile = session.summaryDocumentId?.let {
fileRepository.findById(it, organizationId) // 쿼리 4
}
val materials = classSessionFileRepository.findByClassSessionId(session.id) // 쿼리 5
.mapNotNull { classSessionFile ->
fileRepository.findById(classSessionFile.fileId, organizationId) // 쿼리 6, 7, 8...
}
// ...
}
}문제점:
- 세션 20개 조회 시: 약 161개 쿼리 실행
- 세션 조회: 1개
- 각 세션마다 파일 4개 조회: 20 × 4 = 80개
- 각 세션마다 materials 조회: 20개
- 각 material마다 파일 조회: 20 × 3 = 60개
각 쿼리가 Connection을 점유하고, Connection Usage Time이 450ms로 길어서 연결이 빨리 반환되지 않았습니다. Pool이 고갈되면 새 연결을 생성해야 하는데, Connection Creation Time이 4.5초까지 증가했습니다.
해결 방법
1. 배치 조회 메서드 추가
먼저 Repository 인터페이스에 배치 조회 메서드를 추가했습니다:
// FileRepository.kt
interface FileRepository {
fun findById(id: FileId, organizationId: OrganizationId): File?
fun findAllByIds(ids: List<FileId>, organizationId: OrganizationId): List<File> // 추가
// ...
}
// ClassSessionFileRepository.kt
interface ClassSessionFileRepository {
fun findByClassSessionId(classSessionId: ClassSessionId): List<ClassSessionFile>
fun findAllByClassSessionIds(classSessionIds: List<ClassSessionId>): List<ClassSessionFile> // 추가
// ...
}Spring Data JPA Repository 구현:
// SpringDataFileRepository.kt
interface SpringDataFileRepository : JpaRepository<FileEntity, String> {
fun findByIdAndOrganizationId(id: String, organizationId: String): FileEntity?
fun findAllByIdInAndOrganizationId(ids: List<String>, organizationId: String): List<FileEntity> // 추가
}
// SpringDataClassSessionFileRepository.kt
interface SpringDataClassSessionFileRepository : JpaRepository<ClassSessionFileEntity, String> {
fun findByClassSessionId(classSessionId: String): List<ClassSessionFileEntity>
fun findAllByClassSessionIdIn(classSessionIds: List<String>): List<ClassSessionFileEntity> // 추가
}2. N+1 쿼리 최적화
getSessionsWithFiles 메서드를 배치 조회로 최적화했습니다:
override fun getSessionsWithFiles(
sessions: List<ClassSession>,
organizationId: OrganizationId,
): List<ClassSessionWithFiles> {
if (sessions.isEmpty()) {
return emptyList()
}
// 모든 세션 ID 수집
val sessionIds = sessions.map { it.id }
// 모든 ClassSessionFile을 한 번에 조회 (1개 쿼리)
val allClassSessionFiles = classSessionFileRepository.findAllByClassSessionIds(sessionIds)
val classSessionFilesBySessionId = allClassSessionFiles.groupBy { it.classSessionId }
// 모든 파일 ID 수집 (plan, report, video, summary, materials)
val allFileIds = (
sessions.flatMap {
listOfNotNull(
it.planFileId,
it.reportFileId,
it.classVideoFileId,
it.summaryDocumentId,
)
} + allClassSessionFiles.map { it.fileId }
).toSet()
// 모든 파일을 한 번에 조회 (1개 쿼리)
val allFiles = fileRepository.findAllByIds(allFileIds.toList(), organizationId)
val filesById = allFiles.associateBy { it.id }
// 세션별로 ClassSessionWithFiles 생성 (메모리에서 매핑)
return sessions.map { session ->
val planFile = session.planFileId?.let { filesById[it] }
val reportFile = session.reportFileId?.let { filesById[it] }
val classVideoFile = session.classVideoFileId?.let { filesById[it] }
val summaryDocumentFile = session.summaryDocumentId?.let { filesById[it] }
val materials = classSessionFilesBySessionId[session.id]
?.mapNotNull { classSessionFile ->
filesById[classSessionFile.fileId]
}
?: emptyList()
ClassSessionWithFiles(
session = session,
planFile = planFile,
reportFile = reportFile,
classVideoFile = classVideoFile,
summaryDocumentFile = summaryDocumentFile,
materials = materials,
)
}
}최적화 결과:
- 세션 20개 조회 시: 3개 쿼리만 실행
- 세션 조회: 1개 (이미 완료)
- 모든 ClassSessionFile 배치 조회: 1개
- 모든 파일 배치 조회: 1개
- 쿼리 수: 161개 → 3개 (98% 감소)
3. Connection Pool 크기 조정
Connection Pool 설정을 조정했습니다:
# application-dev.properties
# 변경 전
spring.datasource.hikari.maximum-pool-size=5
spring.datasource.hikari.minimum-idle=2
# 변경 후
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.leak-detection-threshold=60000조정 이유:
- N+1 쿼리 최적화로 Connection 사용 시간이 단축되었지만, 동시 요청이 많을 때를 대비해 Pool 크기를 증가시켰습니다.
- Connection leak 감지 기능도 추가하여 문제를 조기에 발견할 수 있도록 했습니다.
결과
성능 개선 효과
쿼리 수 감소:
- 기존: 161개 쿼리
- 최적화 후: 3개 쿼리
- 98% 감소
Connection Timeout:
- 기존: 27회
- 최적화 후: 0회
- 100% 해결
Connection Pool 상태:
- 기존: Active 최대 4-5개, Pending 최대 5-7개
- 최적화 후: Active 0-4개, Pending 0개, Idle 12개로 안정화
HikariCP 대시보드 개선 사항
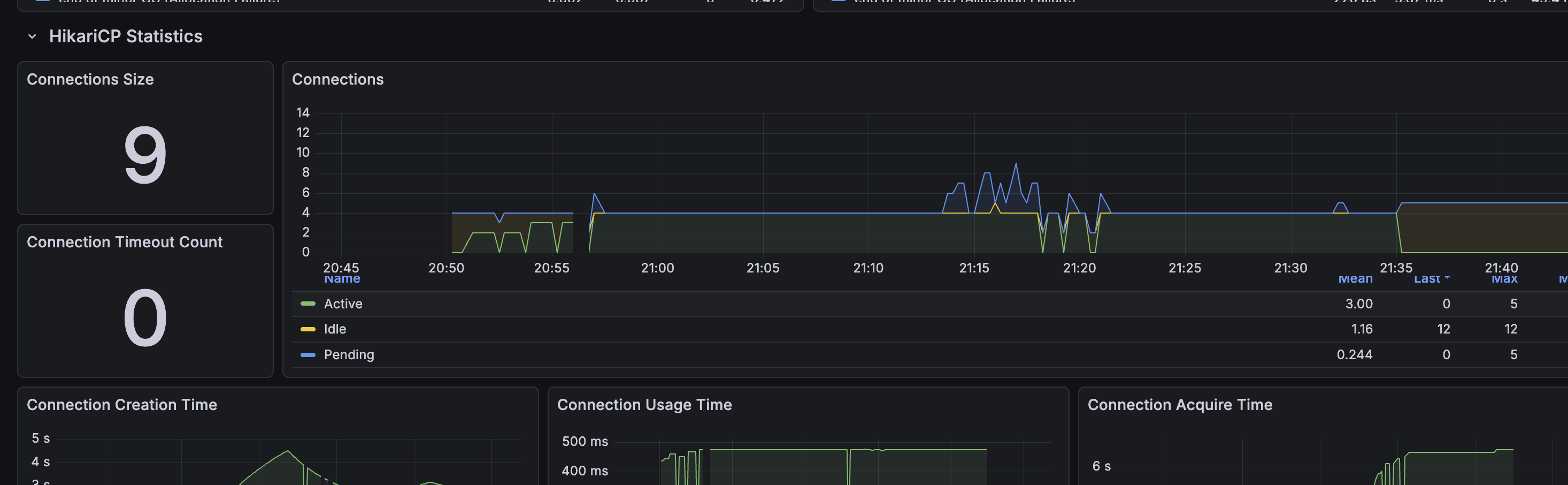
최적화 후 대시보드에서 확인한 개선 사항:
-
Connection Timeout Count: 0 ✅
- 이전: 27회
- 현재: 0회
-
Connection Acquire Time 안정화 ✅
- 이전: 계속 높은 상태 유지
- 현재: 안정화 후 0초로 떨어짐
-
Connection Usage Time 감소 ✅
- 이전: 450ms로 높게 유지
- 현재: 안정화 후 0ms
-
Pending Connections 제거 ✅
- 이전: 최대 5-7개
- 현재: 0개로 안정화
배운 점
1. N+1 쿼리 문제는 배치 조회로 해결
개별 조회를 배치 조회로 변경하면 쿼리 수를 대폭 줄일 수 있습니다. JOIN FETCH도 좋은 방법이지만, 이 경우에는 배치 조회가 더 단순하고 효율적이었습니다.
2. Connection Pool 크기는 모니터링 기반으로 조정
Connection Pool 크기는 트래픽과 쿼리 패턴에 따라 조정해야 합니다. HikariCP 대시보드를 통해 실제 사용량을 모니터링하고, 그에 맞게 조정하는 것이 중요합니다. 단순히 크게 설정하는 것이 아니라, 실제 부하 패턴을 분석한 후 결정해야 합니다.
3. 성능 문제는 체계적으로 분석해야 함
Connection Timeout 문제를 해결하기 위해서는 단순히 Pool 크기만 늘리는 것이 아니라, 근본 원인을 찾아야 합니다. HikariCP 대시보드를 통해 Connection Usage Time, Creation Time, Acquire Time 등을 종합적으로 분석하여 문제의 원인을 파악하고, 그에 맞는 해결책을 적용하는 것이 중요합니다.
결론
N+1 쿼리 최적화와 Connection Pool 튜닝을 통해 Connection Timeout 문제를 완전히 해결했습니다. 쿼리 수는 98% 감소했고, Connection Timeout은 27회에서 0회로 줄었습니다.
성능 최적화는 단순히 코드를 빠르게 만드는 것이 아니라, 사용자 경험을 개선하고 시스템 안정성을 높이는 것입니다. HikariCP 대시보드를 통해 문제를 발견하고, 체계적으로 분석하여 해결한 경험이었습니다.