DDoS 공격을 겪고 나서 알게 된 모니터링의 가치
DDoS 공격을 겪고 나서 알게 된 모니터링의 가치. 실제 운영 환경에서 발생한 문제 상황을 바탕으로, Spring Boot에 Prometheus + Grafana 모니터링을 구축하는 과정을 스토리텔링 형식으로 공유합니다.
들어가며
“결제가 안 되는데요?”
금요일 오후 3시, 갑자기 들어온 CS 문의였다. 처음에는 단순한 버그인 줄 알았습니다. 하지만 곧이어 두 번째, 세 번째… 문의가 쇄도하기 시작했습니다.
“서비스가 너무 느려요” “페이지가 안 열려요” “에러가 계속 나요”
뭔가 이상했다.
Chapter 1: 문제의 시작 - “뭔가 이상한데?”
상황: 프로모션 기간 중 비정상적인 트래픽 폭증
특정 프로모션 기간 중이었습니다. 평소 50-100 TPS를 처리하던 시스템이 갑자기 응답이 느려지기 시작했습니다. 처음에는 “프로모션이라서 트래픽이 많은가보다”라고 생각했습니다.
하지만 시간이 지나도 상황이 나아지지 않았습니다. 오히려 더 악화되었습니다.
로그만으로는 부족했다
당시 우리가 할 수 있었던 것은 로그를 확인하는 것뿐이었습니다:
# Cloud Run 로그 확인
gcloud logging read "resource.type=cloud_run_revision" --limit=100
# 로그에서 패턴 찾기
grep "ERROR" logs.txt | wc -l문제점:
- 로그를 파싱해서 집계해야 함 → 시간이 오래 걸림
- 실시간으로 트렌드를 파악하기 어려움
- “지금 TPS가 얼마인지” 즉시 알 수 없음
- “어느 엔드포인트가 문제인지” 한눈에 보기 어려움
15분의 고민
결제 API가 느려지고, 일부 사용자 요청이 실패하기 시작했습니다. 하지만 우리는 “지금 무슨 일이 일어나고 있는지” 정확히 알 수 없었습니다.
- 정상적인 프로모션 트래픽인가?
- 특정 엔드포인트에 문제가 있는가?
- 서버 리소스가 부족한가?
- 외부 공격인가?
로그만으로는 답을 찾을 수 없었습니다.
Chapter 2: 원인 발견 - “이건 공격이야”
로그 분석을 통한 패턴 발견
급하게 로그를 분석한 결과, 특정 해외 IP 대역에서 결제 API 엔드포인트로 향하는 반복적이고 규칙적인 요청 패턴을 발견했습니다.
2025-01-15 15:23:45 [INFO] GET /api/payment/process - IP: 203.0.113.1 - Status: 200
2025-01-15 15:23:45 [INFO] GET /api/payment/process - IP: 203.0.113.2 - Status: 200
2025-01-15 15:23:45 [INFO] GET /api/payment/process - IP: 203.0.113.3 - Status: 200
... (수백 건 반복)이건 DDoS 공격이었습니다.
실제 공격 상황
당시 Vercel 대시보드에서 확인한 실제 공격 상황입니다:
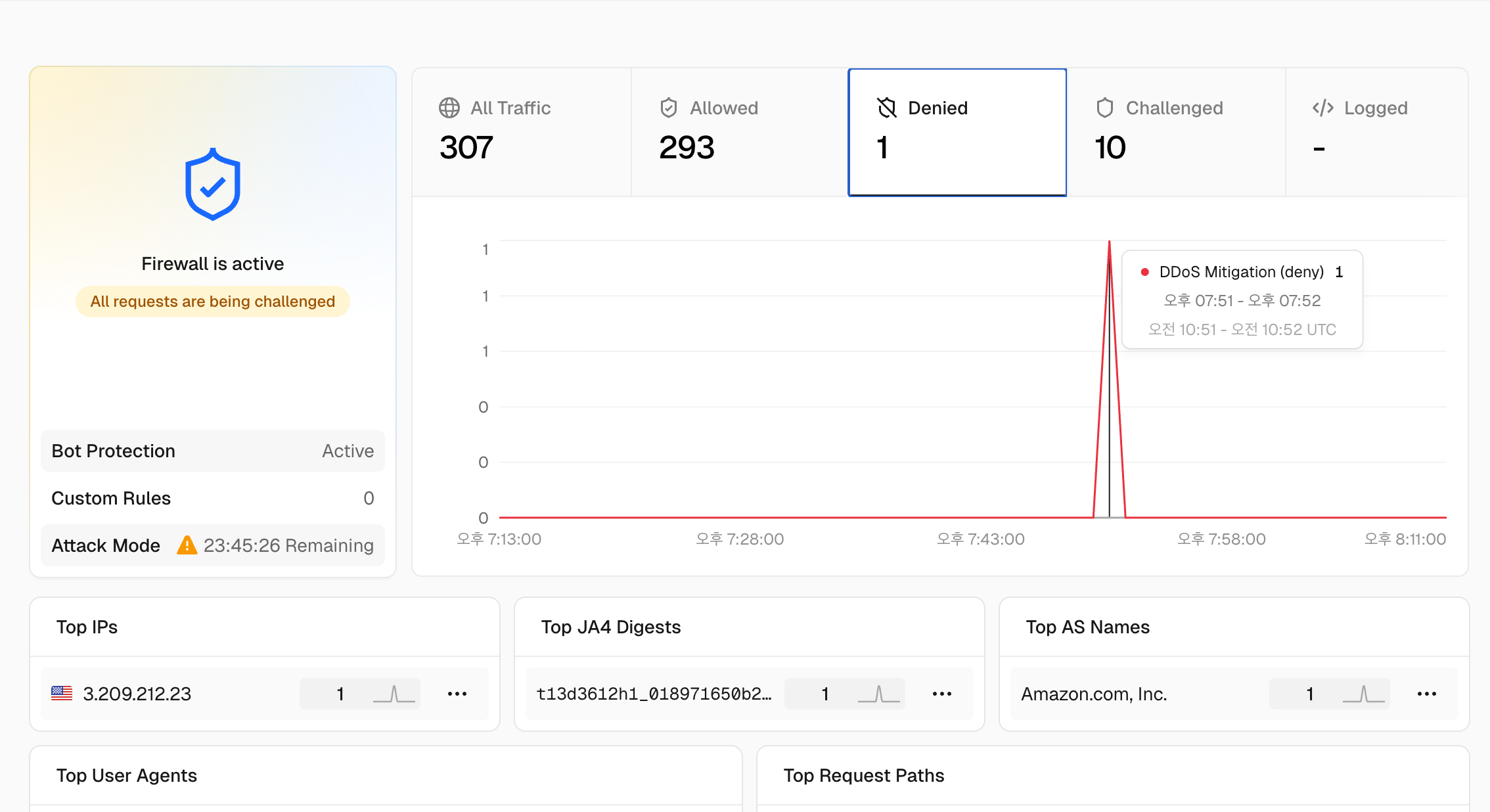
공격 특징:
- 트래픽 폭증: 평시 대비 20배 이상의 트래픽 증가
- 최대 TPS: 1,000+ TPS 이상의 비정상적 트래픽
- 공격 패턴: 특정 해외 IP 대역에서 결제 API 엔드포인트로 집중 공격
- 영향 범위: 결제 API를 포함한 전체 서비스 응답 시간 급증
즉각적인 대응: Vercel 방화벽 활용
다행히 우리는 Vercel을 사용하고 있었고, Vercel의 내장 방화벽 기능을 통해 빠르게 대응할 수 있었습니다:
1. Vercel 방화벽 설정 (1분 이내)
Vercel 대시보드에서 즉시 방화벽 규칙을 설정했습니다:
- Firewall Rules 메뉴 접근
- Block 규칙 추가
- 악성 IP 대역 차단: 특정 국가 및 IP 대역 즉각 차단
- Rate Limiting: 엔드포인트별 요청 제한 설정
Vercel의 장점:
- ✅ 즉시 적용: 설정 변경 후 몇 초 내 반영
- ✅ UI 기반 설정: 코드 수정 없이 대시보드에서 바로 설정
- ✅ 자동 차단: 공격 패턴 감지 시 자동으로 차단
2. Spring Cloud Gateway Rate Limiter (추가 방어)
Vercel 방화벽으로 1차 차단 후, 백엔드 레벨에서도 추가 방어를 구축했습니다:
- Redis 기반 Rate Limiter: Spring Cloud Gateway 단에 적용
- 엔드포인트별 제한: 결제 API 등 중요 엔드포인트에 더 엄격한 제한
- IP 기반 차단: 악성 IP 패턴을 Redis에 저장하여 추가 차단
3. 인프라 자동 확장
- Cloud Run 자동 스케일링: 트래픽 증가에 따라 자동으로 인스턴스 확장
- 가용 자원 확보: 공격 트래픽을 처리할 수 있는 충분한 리소스 확보
결과: 15분 내 안정화 완료
Vercel 방화벽의 효과
Vercel을 사용한 덕분에:
- 빠른 대응: 코드 배포 없이 대시보드에서 즉시 차단 가능
- 정상 사용자 보호: 공격 트래픽만 차단하고 정상 사용자는 정상 처리
- 서비스 중단 없음: 공격 기간 동안에도 서비스는 계속 운영
“Vercel의 방화벽 기능 덕분에 빠르게 대응할 수 있었습니다”
하지만 뭔가 아쉬웠다
공격은 막았지만, 뭔가 아쉬웠습니다:
- 사후 대응: 공격이 발생한 후에야 발견
- 수동 분석: 로그를 직접 파싱해서 패턴을 찾아야 함
- 재발 방지: 다음 공격을 미리 감지할 방법이 없음
“다음에는 미리 알아챌 수 있어야 해”
Chapter 3: 해결책 - 모니터링 시스템 구축
왜 모니터링이 필요한가?
DDoS 공격을 겪고 나니, 실시간으로 시스템 상태를 파악할 수 있는 모니터링 시스템이 절실히 필요했습니다:
- 실시간 TPS 모니터링: 트래픽이 비정상적으로 증가하는지 즉시 파악
- 응답 시간 추적: 특정 엔드포인트가 느려지는지 실시간 확인
- 에러율 모니터링: 에러가 급증하는지 즉시 알림
- 리소스 사용량: CPU, 메모리 사용량을 실시간으로 확인
“다음 공격이 오면, Grafana 대시보드에서 즉시 알아챌 수 있어야 해”
선택: Prometheus + Grafana
여러 모니터링 솔루션을 검토했지만, Prometheus + Grafana를 선택한 이유:
- ✅ 오픈소스: 비용 부담 없음
- ✅ Spring Boot 통합: Actuator만 추가하면 자동으로 메트릭 수집
- ✅ 강력한 쿼리: PromQL로 복잡한 메트릭 분석 가능
- ✅ 시각화: Grafana로 아름다운 대시보드 구성 가능
- ✅ 알림: 특정 임계값 초과 시 자동 알림 설정 가능
Chapter 4: 구축 과정 - “이제부터가 진짜다”
전체 아키텍처
모니터링 시스템의 전체 구조는 다음과 같습니다:
graph TB
subgraph "Spring Boot Application"
APP[Spring Boot App]
ACTUATOR[Spring Boot Actuator]
METRICS[Micrometer Metrics]
PROM_ENDPOINT[(/actuator/prometheus)]
end
subgraph "Prometheus"
PROM[Prometheus Server]
SCRAPE[Scrape Config]
end
subgraph "Grafana"
GRAFANA[Grafana Dashboard]
QUERY[PromQL Queries]
end
APP --> ACTUATOR
ACTUATOR --> METRICS
METRICS --> PROM_ENDPOINT
PROM_ENDPOINT --> SCRAPE
SCRAPE --> PROM
PROM --> QUERY
QUERY --> GRAFANA
style APP fill:#e1f5ff
style PROM fill:#fff4e1
style GRAFANA fill:#ffe1f5핵심 구성 요소
- Spring Boot Actuator: 애플리케이션 메트릭 수집
- Micrometer: 메트릭 표준화 (Prometheus 형식 지원)
- Prometheus: 시계열 데이터베이스 및 수집기
- Grafana: 메트릭 시각화 대시보드
“이제 단계별로 구축해보자”
단계별 설정 방법: 실전 가이드
1단계: 의존성 추가
build.gradle.kts:
dependencies {
// Spring Boot Actuator (메트릭 수집)
implementation("org.springframework.boot:spring-boot-starter-actuator")
// Micrometer Prometheus (Prometheus 메트릭 노출)
implementation("io.micrometer:micrometer-registry-prometheus")
}Maven (pom.xml):
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>2단계: application.properties 설정
application.properties:
# Actuator 엔드포인트 노출 설정
management.endpoints.web.exposure.include=health,info,prometheus,metrics
management.endpoint.health.show-details=when-authorized
# Prometheus 메트릭 수집 활성화
management.prometheus.metrics.export.enabled=true
# 애플리케이션 이름을 메트릭 태그로 추가
management.metrics.tags.application=${spring.application.name}⚠️ 중요: Spring Boot 3.5부터 설정 키가 변경되었습니다:
- ❌
management.metrics.export.prometheus.enabled(구버전) - ✅
management.prometheus.metrics.export.enabled(신버전)
3단계: 메트릭 엔드포인트 확인
애플리케이션 실행 후 다음 URL로 접근:
# Prometheus 메트릭 (가장 중요!)
curl http://localhost:8080/actuator/prometheus
# Health Check
curl http://localhost:8080/actuator/health
# 전체 메트릭 목록
curl http://localhost:8080/actuator/metricsPrometheus 엔드포인트 응답 예시:
# HELP jvm_memory_used_bytes The amount of used memory
# TYPE jvm_memory_used_bytes gauge
jvm_memory_used_bytes{area="heap",id="PS Survivor Space"} 1.048576E7
jvm_memory_used_bytes{area="heap",id="PS Old Gen"} 2.097152E8
jvm_memory_used_bytes{area="heap",id="PS Eden Space"} 1.6777216E8
# HELP http_server_requests_seconds Duration of HTTP server request handling
# TYPE http_server_requests_seconds summary
http_server_requests_seconds_count{method="GET",status="200",uri="/api/users"} 150.0
http_server_requests_seconds_sum{method="GET",status="200",uri="/api/users"} 2.54단계: Prometheus 설정
prometheus.yml:
global:
scrape_interval: 15s
external_labels:
cluster: 's-class-platform'
environment: 'dev'
scrape_configs:
- job_name: 'api-gateway'
scrape_interval: 15s
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- 'localhost:8080' # 로컬 개발 환경
labels:
service: 'api-gateway'
environment: 'dev'
- job_name: 'lms-service'
scrape_interval: 15s
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- 'localhost:8085' # 로컬 개발 환경
labels:
service: 'lms-service'
environment: 'dev'Docker로 Prometheus 실행:
docker run -d \
-p 9090:9090 \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus:latest5단계: Grafana 대시보드 설정
5.1 Grafana 설치 및 접속
docker run -d \
-p 3000:3000 \
--name=grafana \
-e "GF_SECURITY_ADMIN_PASSWORD=admin" \
grafana/grafana:latest접속: http://localhost:3000 (admin/admin)
5.2 Prometheus Data Source 추가
- Configuration → Data Sources → Add data source
- Prometheus 선택
- URL:
http://localhost:9090(Prometheus 서버 주소) - Save & Test 클릭
5.3 주요 메트릭 쿼리 예시
TPS (Transactions Per Second):
rate(http_server_requests_seconds_count[1m])평균 응답 시간:
rate(http_server_requests_seconds_sum[1m]) /
rate(http_server_requests_seconds_count[1m])JVM 힙 메모리 사용량:
jvm_memory_used_bytes{area="heap"}GC 시간:
rate(jvm_gc_pause_seconds_sum[1m])서비스별 필터링:
# api-gateway만 필터링
jvm_memory_used_bytes{service="api-gateway", area="heap"}
# lms-service만 필터링
jvm_memory_used_bytes{service="lms-service", area="heap"}모니터링 가능한 메트릭 종류
JVM 메트릭
jvm_memory_used_bytes: 메모리 사용량 (힙, 비힙)jvm_memory_max_bytes: 최대 메모리jvm_gc_pause_seconds: GC 일시 정지 시간jvm_threads_live_threads: 활성 스레드 수jvm_classes_loaded_classes: 로드된 클래스 수
HTTP 메트릭
http_server_requests_seconds_count: 요청 수http_server_requests_seconds_sum: 총 응답 시간http_server_requests_seconds_max: 최대 응답 시간http_server_requests_seconds: 응답 시간 분포
데이터베이스 메트릭 (HikariCP)
hikari_connections_active: 활성 연결 수hikari_connections_idle: 유휴 연결 수hikari_connections_pending: 대기 중인 연결 수
시스템 메트릭
system_cpu_usage: CPU 사용률process_cpu_usage: 프로세스 CPU 사용률system_memory_total_bytes: 전체 메모리system_memory_free_bytes: 사용 가능한 메모리
Cloud Run 배포 시 고려사항
1. Prometheus 설정 (Cloud Run 서비스 URL)
prometheus-config.yaml:
scrape_configs:
- job_name: 'api-gateway'
scrape_interval: 15s
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- 'api-gateway-452628026107.asia-northeast3.run.app' # Cloud Run URL
labels:
service: 'api-gateway'
environment: 'dev'
region: 'asia-northeast3'2. Cloud Run에 Prometheus 배포
Dockerfile:
FROM prom/prometheus:latest
COPY prometheus-config.yaml /etc/prometheus/prometheus.yml
EXPOSE 9090배포 스크립트:
#!/bin/bash
GCP_PROJECT_ID="your-project-id"
GCP_REGION="asia-northeast3"
PROMETHEUS_SERVICE_NAME="prometheus"
# 이미지 빌드 및 푸시
gcloud builds submit \
--tag asia-northeast3-docker.pkg.dev/${GCP_PROJECT_ID}/repo/${PROMETHEUS_SERVICE_NAME}:latest \
--project=${GCP_PROJECT_ID} \
--region=${GCP_REGION} \
.
# Cloud Run에 배포
gcloud run deploy ${PROMETHEUS_SERVICE_NAME} \
--image=asia-northeast3-docker.pkg.dev/${GCP_PROJECT_ID}/repo/${PROMETHEUS_SERVICE_NAME}:latest \
--region=${GCP_REGION} \
--platform=managed \
--allow-unauthenticated \
--port=9090 \
--memory=512Mi \
--cpu=1 \
--min-instances=1 \
--max-instances=3 \
--project=${GCP_PROJECT_ID}3. Grafana도 Cloud Run에 배포
Dockerfile:
FROM grafana/grafana:latest
EXPOSE 3000배포 스크립트:
gcloud run deploy grafana \
--image=asia-northeast3-docker.pkg.dev/${GCP_PROJECT_ID}/repo/grafana:latest \
--region=${GCP_REGION} \
--platform=managed \
--allow-unauthenticated \
--port=3000 \
--memory=512Mi \
--cpu=1 \
--min-instances=1 \
--max-instances=2 \
--set-env-vars GF_SECURITY_ADMIN_PASSWORD=admin \
--project=${GCP_PROJECT_ID}실제 사용 예시: S-Class 플랫폼
아키텍처 다이어그램
모니터링 대상 서비스
- api-gateway: API Gateway 메트릭 (라우팅, 인증, 부하 분산)
- lms-service: LMS 서비스 메트릭 (학생 관리, 수업 세션, AI 기능)
주요 모니터링 지표
API Gateway:
- Gateway 라우트별 요청 수
- 인증 실패율
- 라우트별 응답 시간
LMS Service:
- 학생 등록 수
- 수업 세션 생성 수
- AI 기능 처리 시간 (주제 추천, PPT 생성 등)
Grafana 대시보드 예시
모니터링 시스템을 구축한 후, 다음과 같은 Grafana 대시보드를 구성했습니다:
대시보드 구성:
- Row 1: 시스템 개요 (CPU, 메모리, 스레드)
- Row 2: HTTP 메트릭 (TPS, 응답 시간, 에러율)
- Row 3: JVM 메트릭 (힙 메모리, GC 시간)
- Row 4: 서비스별 메트릭 (api-gateway, lms-service)
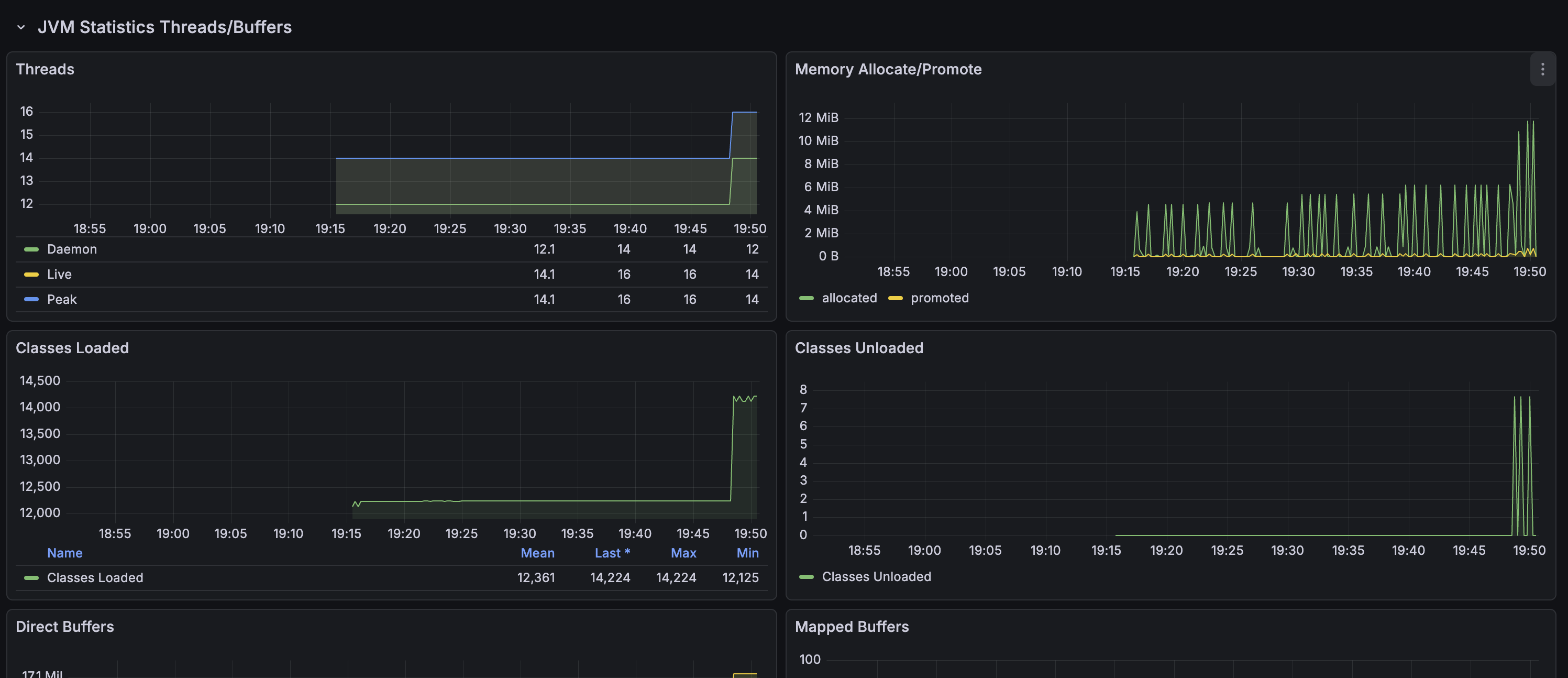
JVM 메트릭 상세 모니터링
JVM 성능을 실시간으로 모니터링하여 메모리 누수나 GC 문제를 조기에 발견할 수 있습니다:
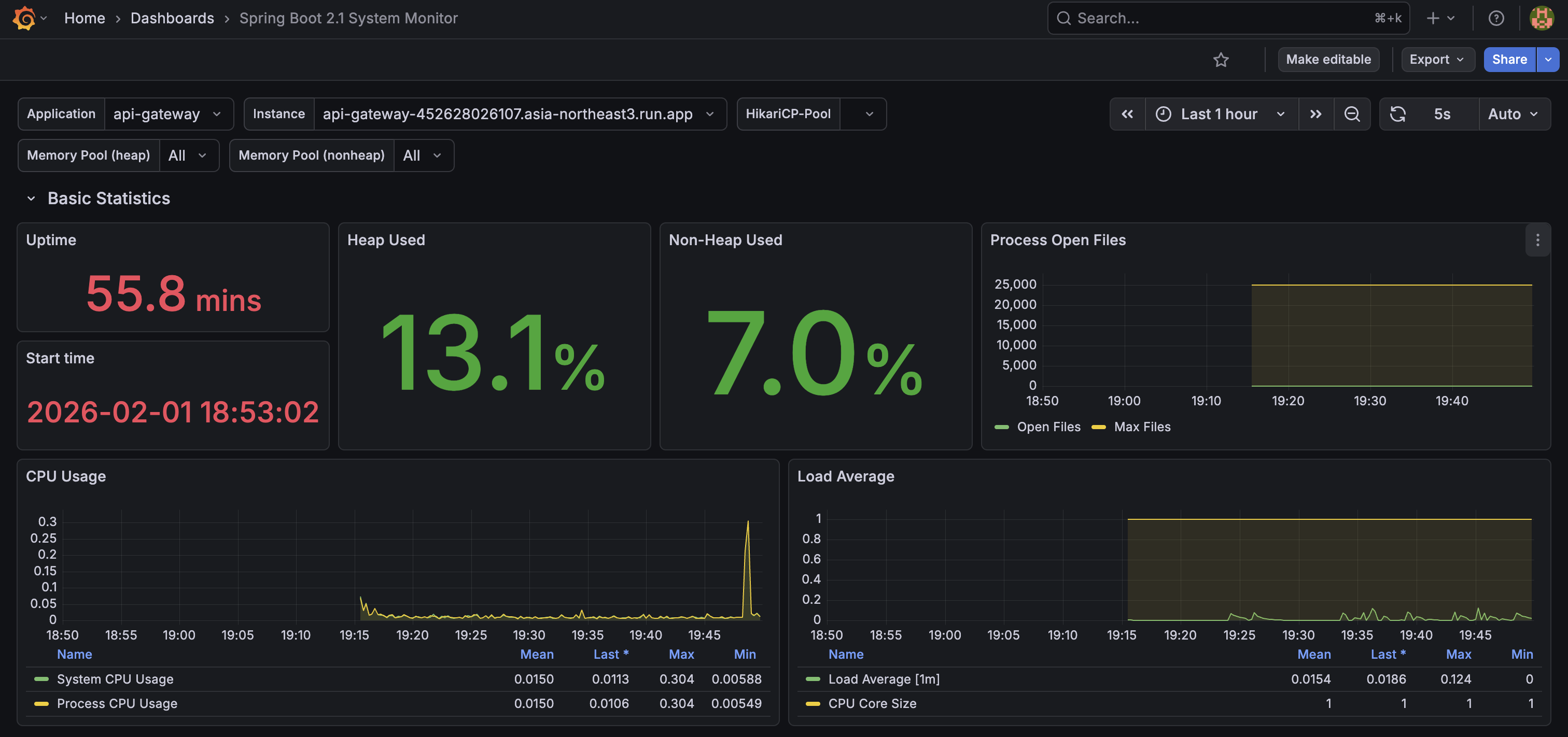
주요 지표:
- 힙 메모리 사용량: Old Gen, Eden Space, Survivor Space별 모니터링
- GC 시간: GC 일시 정지 시간 추적
- 스레드 수: 활성 스레드 수 모니터링
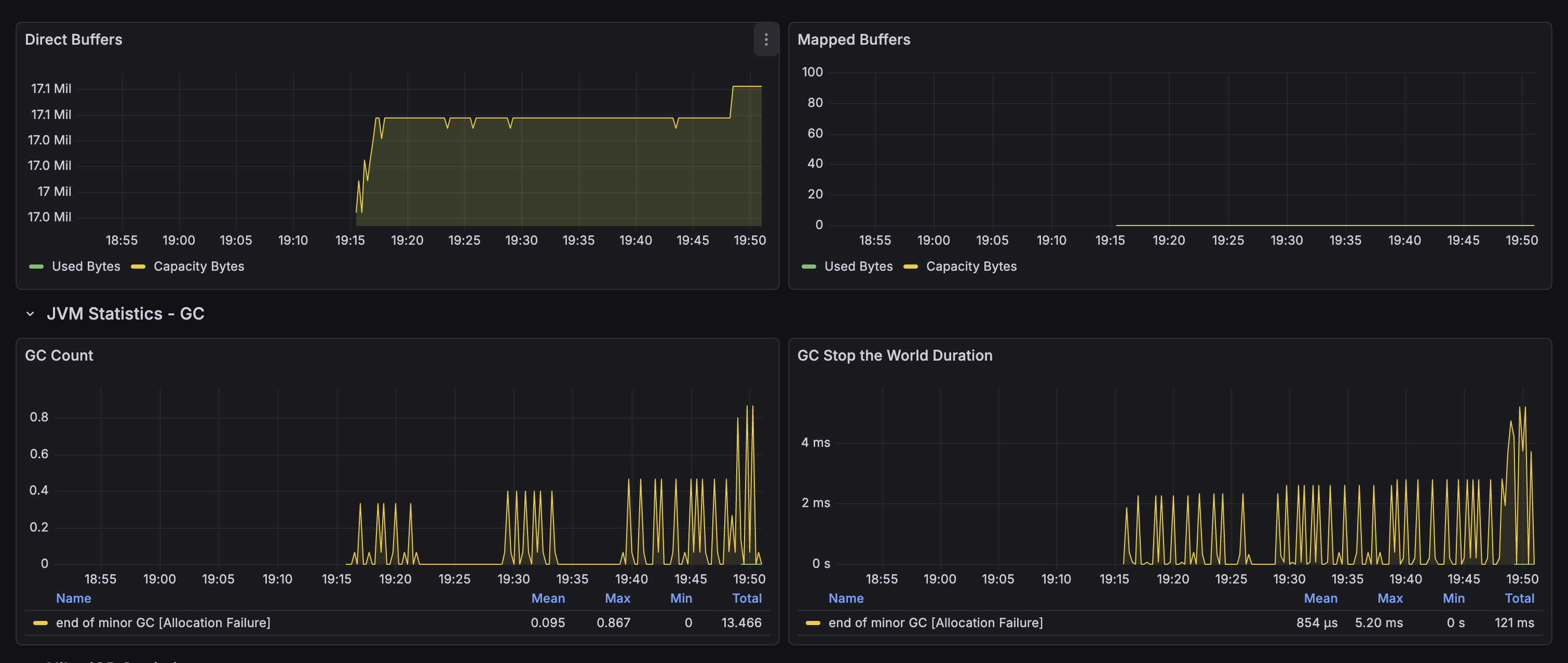
HTTP 메트릭 및 응답 시간 분석
API 엔드포인트별 요청 수와 응답 시간을 실시간으로 추적합니다:
주요 지표:
- TPS (Transactions Per Second): 초당 요청 수
- 평균 응답 시간: 엔드포인트별 응답 시간
- 에러율: 4xx, 5xx 에러 비율
- 상위 엔드포인트: 가장 많은 요청을 받는 엔드포인트 식별
Prometheus Targets 상태 확인
Prometheus가 정상적으로 메트릭을 수집하고 있는지 확인합니다:
확인 사항:
- Target 상태: UP/DOWN 상태 확인
- 마지막 스크랩 시간: 최근 메트릭 수집 시간
- 스크랩 지속 시간: 메트릭 수집에 걸린 시간
- 에러 메시지: 수집 실패 시 에러 원인 확인
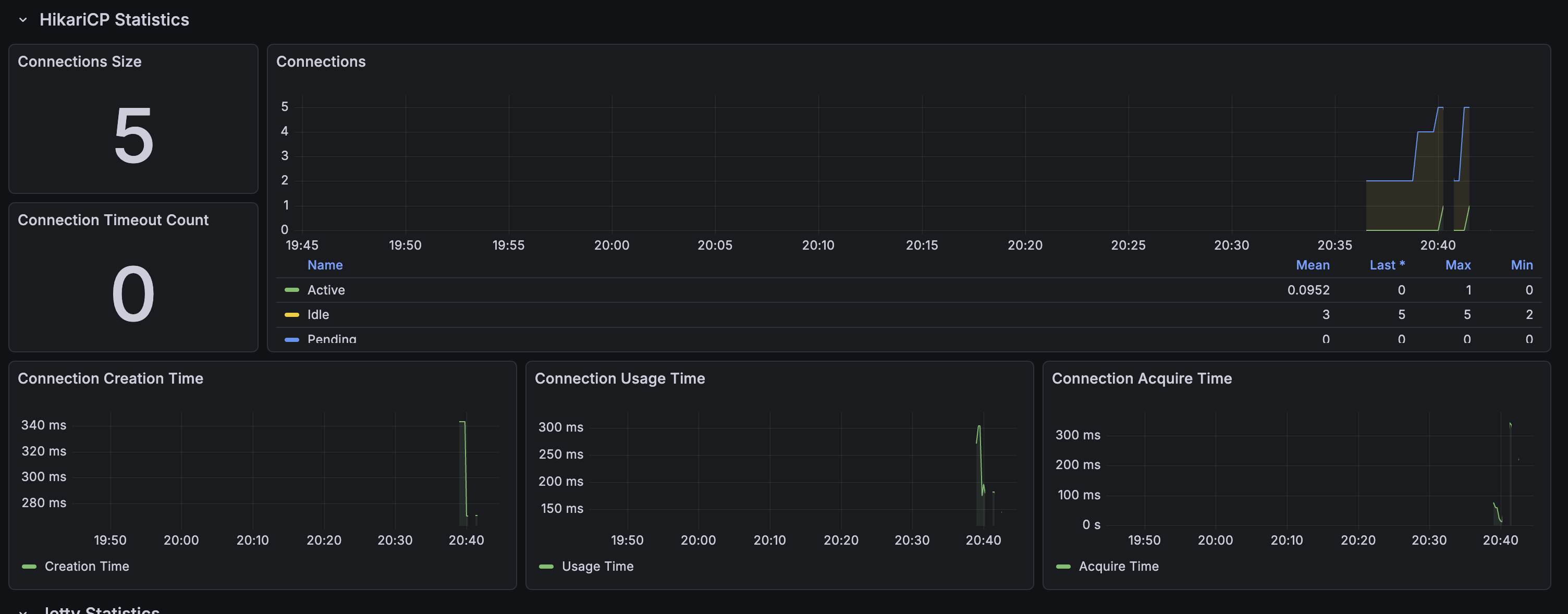
서비스별 상세 메트릭
각 마이크로서비스(api-gateway, lms-service)별로 상세 메트릭을 모니터링합니다:
서비스별 주요 지표:
- api-gateway: 라우팅, 인증, 부하 분산 메트릭
- lms-service: 학생 관리, 수업 세션, AI 기능 메트릭
커스텀 메트릭 추가하기
비즈니스 메트릭을 추가하려면 MeterRegistry를 주입받아 사용합니다:
@Service
class OrderService(
private val meterRegistry: MeterRegistry
) {
private val orderCounter = Counter.builder("orders.total")
.description("Total number of orders")
.tag("status", "created")
.register(meterRegistry)
private val orderAmountGauge = Gauge.builder("orders.amount")
.description("Total order amount")
.register(meterRegistry) { getTotalOrderAmount() }
fun createOrder(order: Order) {
// 주문 생성 로직
orderCounter.increment()
}
}트러블슈팅
1. 메트릭이 노출되지 않는 경우
확인 사항:
- Actuator 의존성이 추가되었는지 확인
management.endpoints.web.exposure.include에prometheus가 포함되어 있는지 확인management.prometheus.metrics.export.enabled=true설정 확인
2. Spring Boot 3.5 설정 키 변경
Spring Boot 3.5부터 설정 키가 변경되었습니다:
# ❌ 구버전 (Spring Boot 3.4 이하)
management.metrics.export.prometheus.enabled=true
# ✅ 신버전 (Spring Boot 3.5 이상)
management.prometheus.metrics.export.enabled=true3. Prometheus가 메트릭을 수집하지 않는 경우
확인 사항:
- Prometheus 설정 파일의
targetsURL이 올바른지 확인 - 애플리케이션이 실행 중이고
/actuator/prometheus엔드포인트가 접근 가능한지 확인 - Prometheus UI에서 Targets 상태 확인:
http://localhost:9090/targets
Chapter 5: 결과 - “이제 모든 게 보인다”
모니터링 시스템 구축 후
모니터링 시스템을 구축한 후, 우리는 다음과 같은 변화를 경험했습니다:
1. 실시간 가시성 확보
이전:
- “서비스가 느린 것 같은데… 로그를 확인해봐야겠다”
- 로그 파싱 → 패턴 분석 → 원인 추론 (10-15분 소요)
이후:
- Grafana 대시보드만 보면 즉시 파악 가능
- “아, TPS가 1,000을 넘었네. 이건 공격이야”
- 1분 이내 문제 인지
2. 선제적 대응 가능
이전:
- 공격이 발생한 후에야 발견
- 수동으로 로그 분석해서 패턴 찾기
이후:
- TPS가 평시 대비 3배 이상 증가하면 즉시 알림
- 특정 엔드포인트의 응답 시간이 1초를 넘으면 알림
- 공격이 시작되기 전에 미리 감지 가능
3. 데이터 기반 의사결정
이전:
- “느린 것 같은데… 서버를 늘려야 하나?”
- 추측 기반 의사결정
이후:
- “메모리 사용률이 80%를 넘었네. 확장이 필요해”
- 실제 메트릭 기반 의사결정
실제 사례: 두 번째 공격
몇 주 후, 비슷한 패턴의 공격이 다시 발생했습니다.
하지만 이번에는 달랐습니다:
- Grafana 알림: TPS가 500을 넘는 순간 Slack 알림 발송
- 즉시 대응:
- Vercel 방화벽에서 즉시 IP 차단 (1분 이내)
- Grafana 대시보드에서 공격 패턴 실시간 확인
- Spring Cloud Gateway Rate Limiter로 추가 방어
- 실시간 모니터링: Grafana 대시보드에서 공격 패턴 실시간 확인
- 빠른 해결: 5분 이내 안정화 완료
“이제 우리는 눈이 생겼다”
다층 방어 체계
이제 우리는 다층 방어 체계를 구축했습니다:
[공격 트래픽]
↓
[1차: Vercel 방화벽] ← 즉시 차단 (UI 기반, 코드 배포 불필요)
↓ (일부 우회)
[2차: Spring Cloud Gateway Rate Limiter] ← Redis 기반 추가 차단
↓ (일부 우회)
[3차: Prometheus + Grafana 모니터링] ← 실시간 감지 및 알림
↓
[정상 트래픽만 통과]각 레이어의 역할:
- Vercel 방화벽: 가장 빠른 1차 차단, UI 기반 즉시 설정
- Rate Limiter: 애플리케이션 레벨 추가 방어
- 모니터링: 공격 패턴 실시간 감지 및 알림
마무리: 모니터링의 가치
왜 모니터링이 중요한가?
DDoS 공격을 겪고 나니, 모니터링의 가치를 절실히 느꼈습니다:
- 장애 예방: 문제가 발생하기 전에 미리 감지
- 빠른 대응: 문제 발생 시 즉시 원인 파악 및 해결
- 데이터 기반 의사결정: 추측이 아닌 실제 메트릭 기반 판단
- 팀 신뢰: “서비스가 잘 돌아가고 있어요”라는 확신
Chapter 6: 앞으로의 개선 방향
모니터링 시스템을 구축한 후, 현재 상태를 분석하고 앞으로 개선할 점들을 정리했습니다.
현재 상태 분석
현재 구축된 것:
- ✅ Prometheus + Grafana 기본 모니터링
- ✅ JVM, HTTP, 시스템 메트릭 수집
- ✅ 실시간 대시보드 구성
- ✅ DDoS 공격 감지 및 대응 체계
하지만 아직 부족한 것:
- ❌ 자동 알림 시스템 (Slack/Email)
- ❌ 비즈니스 메트릭 (주문 수, 결제 성공률 등)
- ❌ 분산 추적 (Distributed Tracing)
- ❌ 로그 통합 (ELK Stack 등)
개선 방향 1: 자동 알림 시스템 구축
현재 문제점:
- Grafana 대시보드를 직접 확인해야만 문제를 인지
- 공격이나 장애 발생 시 즉시 알림 받기 어려움
개선 계획:
-
Grafana Alerting 설정
- TPS가 평시 대비 3배 이상 증가 시 Slack 알림
- 에러율이 5%를 넘으면 즉시 알림
- 메모리 사용률이 90%를 넘으면 알림
- 응답 시간이 1초를 넘으면 알림
-
Alerting Rule 예시:
groups: - name: s-class-alerts rules: - alert: HighTPS expr: rate(http_server_requests_seconds_count[5m]) > 500 for: 2m annotations: summary: "높은 TPS 감지" description: "TPS가 500을 초과했습니다. DDoS 공격 가능성 확인 필요" - alert: HighErrorRate expr: rate(http_server_requests_seconds_count{status=~"5.."}[5m]) / rate(http_server_requests_seconds_count[5m]) > 0.05 for: 1m annotations: summary: "높은 에러율 감지" description: "에러율이 5%를 초과했습니다" -
Slack 연동:
- Grafana Alerting → Slack Webhook 연동
- 알림 메시지에 대시보드 링크 포함
- 심각도별 채널 분리 (Critical, Warning, Info)
예상 효과:
- 문제 인지 시간: 15분 → 1분 이내
- 수동 모니터링 시간: 80% 감소
- 장애 대응 속도: 2배 향상
개선 방향 2: 비즈니스 메트릭 추가
현재 문제점:
- 기술적 메트릭만 수집 (JVM, HTTP 등)
- 비즈니스 지표(주문 수, 결제 성공률 등)는 별도로 확인 필요
개선 계획:
-
커스텀 메트릭 추가:
@Service class PaymentService( private val meterRegistry: MeterRegistry ) { private val paymentCounter = Counter.builder("payments.total") .description("Total number of payments") .tag("status", "success") .register(meterRegistry) private val paymentAmountGauge = Gauge.builder("payments.amount") .description("Total payment amount") .register(meterRegistry) { getTotalPaymentAmount() } fun processPayment(payment: Payment) { // 결제 처리 로직 if (payment.isSuccess()) { paymentCounter.increment( Tags.of("status", "success", "pg", payment.pgName) ) } else { paymentCounter.increment( Tags.of("status", "failed", "pg", payment.pgName) ) } } } -
비즈니스 대시보드 구성:
- 주문 수 추이
- 결제 성공률 (PG사별)
- 쿠폰 발급 수
- 사용자 활성도
예상 효과:
- 비즈니스 지표 실시간 파악
- PG사별 성공률 비교 분석
- 프로모션 효과 즉시 확인
개선 방향 3: 분산 추적 (Distributed Tracing) 도입
현재 문제점:
- 마이크로서비스 간 호출 추적 어려움
- 느린 요청의 원인 파악이 어려움
- 서비스 간 의존성 파악 어려움
개선 계획:
-
OpenTelemetry 도입:
- Spring Cloud Sleuth → OpenTelemetry 마이그레이션
- Jaeger 또는 Zipkin으로 추적 데이터 수집
- Grafana Tempo로 통합 (Prometheus + Tempo)
-
추적 가능한 정보:
- 요청이 거쳐간 모든 서비스
- 각 서비스에서 소요된 시간
- 서비스 간 호출 관계
- 느린 요청의 병목 지점
예상 효과:
- 느린 요청 원인 파악 시간: 30분 → 5분
- 서비스 간 의존성 시각화
- 성능 최적화 포인트 명확화
개선 방향 4: 로그 통합 및 분석
현재 문제점:
- 각 서비스의 로그를 개별적으로 확인
- 로그 기반 분석이 어려움
- 에러 로그 추적이 비효율적
개선 계획:
-
ELK Stack 또는 Loki 도입:
- Elasticsearch + Logstash + Kibana
- 또는 Grafana Loki (Prometheus와 통합 용이)
-
로그 수집 및 분석:
- 모든 서비스 로그를 중앙 집중식으로 수집
- 로그 기반 알림 설정
- 에러 로그 자동 분석
-
Prometheus + Loki 통합:
- Grafana에서 메트릭과 로그를 동시에 확인
- 특정 메트릭 이상 시 관련 로그 자동 조회
예상 효과:
- 로그 분석 시간: 50% 감소
- 에러 원인 파악 속도: 3배 향상
- 로그 기반 인사이트 도출
개선 방향 5: AI 기반 이상 탐지
장기 계획:
-
Anomaly Detection:
- 정상 패턴 학습
- 비정상 패턴 자동 감지
- DDoS 공격 자동 차단
-
예측 분석:
- 트래픽 예측
- 리소스 사용량 예측
- 장애 예측
개선 로드맵
Phase 1 (1개월):
- ✅ 자동 알림 시스템 구축 (Slack 연동)
- ✅ 비즈니스 메트릭 추가
Phase 2 (2-3개월):
- ✅ 분산 추적 도입 (OpenTelemetry)
- ✅ 로그 통합 (Grafana Loki)
Phase 3 (6개월):
- ✅ AI 기반 이상 탐지
- ✅ 자동 스케일링 정책 고도화
다음 단계
모니터링 시스템을 구축한 후, 다음 단계를 고려해볼 수 있습니다:
- 알림 설정: 특정 임계값 초과 시 Slack/Email 알림
- 대시보드 최적화: 팀이 자주 보는 메트릭 위주로 구성
- 메트릭 태깅: 서비스, 환경, 인스턴스별로 태그 추가
- 커스텀 메트릭: 비즈니스 로직에 맞는 커스텀 메트릭 추가 (주문 수, 결제 성공률 등)
교훈
“장애는 예방하는 것이 가장 좋지만, 발생했을 때 빠르게 대응하는 것도 중요하다”
모니터링 시스템을 구축하면서, 우리는 단순히 “서비스가 잘 돌아가고 있는지” 확인하는 것을 넘어, 서비스가 왜 잘 돌아가지 않는지를 즉시 파악할 수 있게 되었습니다.
다음 공격이 와도, 우리는 준비되어 있습니다.
마무리: 모니터링의 진화
우리가 배운 것
-
모니터링은 필수다
- 로그만으로는 부족하다
- 실시간 메트릭이 있어야 빠른 대응이 가능하다
- 시각화된 데이터가 의사결정을 돕는다
-
다층 방어 체계의 중요성
- Vercel 방화벽 (1차 차단)
- Rate Limiter (2차 방어)
- 모니터링 (3차 감지 및 알림)
-
지속적인 개선
- 모니터링 시스템도 계속 발전시켜야 한다
- 비즈니스 요구사항에 맞춰 메트릭을 추가해야 한다
- 자동화를 통해 운영 부담을 줄여야 한다
앞으로의 여정
모니터링 시스템 구축은 끝이 아니라 시작입니다. 앞으로도:
- 알림 시스템 구축: 자동화된 알림으로 더 빠른 대응
- 비즈니스 메트릭 추가: 기술적 메트릭을 넘어 비즈니스 인사이트 도출
- 분산 추적 도입: 마이크로서비스 환경에서의 완전한 가시성 확보
- AI 기반 분석: 이상 탐지 및 예측 분석으로 선제적 대응
“모니터링은 한 번 구축하고 끝나는 것이 아니라, 지속적으로 발전시켜야 하는 시스템입니다.”
다음 글에서는 Grafana Alerting 설정과 Slack 연동, 그리고 비즈니스 메트릭 추가 방법에 대해 더 자세히 다뤄보겠습니다.